5.4 图分类
有时数据不是以一个大型图的形式存在,而是以多个图的形式存在,例如不同类型人群社区的列表。通过用图来描述同一社区中人们的友谊关系,可以得到一个图列表用于分类。在这种情况下,图分类模型可以帮助识别社区的类型,即根据结构和整体信息对每个图进行分类。
概览
图分类与节点分类或链接预测的主要区别在于,预测结果描述的是整个输入图的属性。可以像之前的任务一样在节点/边上执行消息传递,但还需要获取图级别的表示。
图分类流程如下
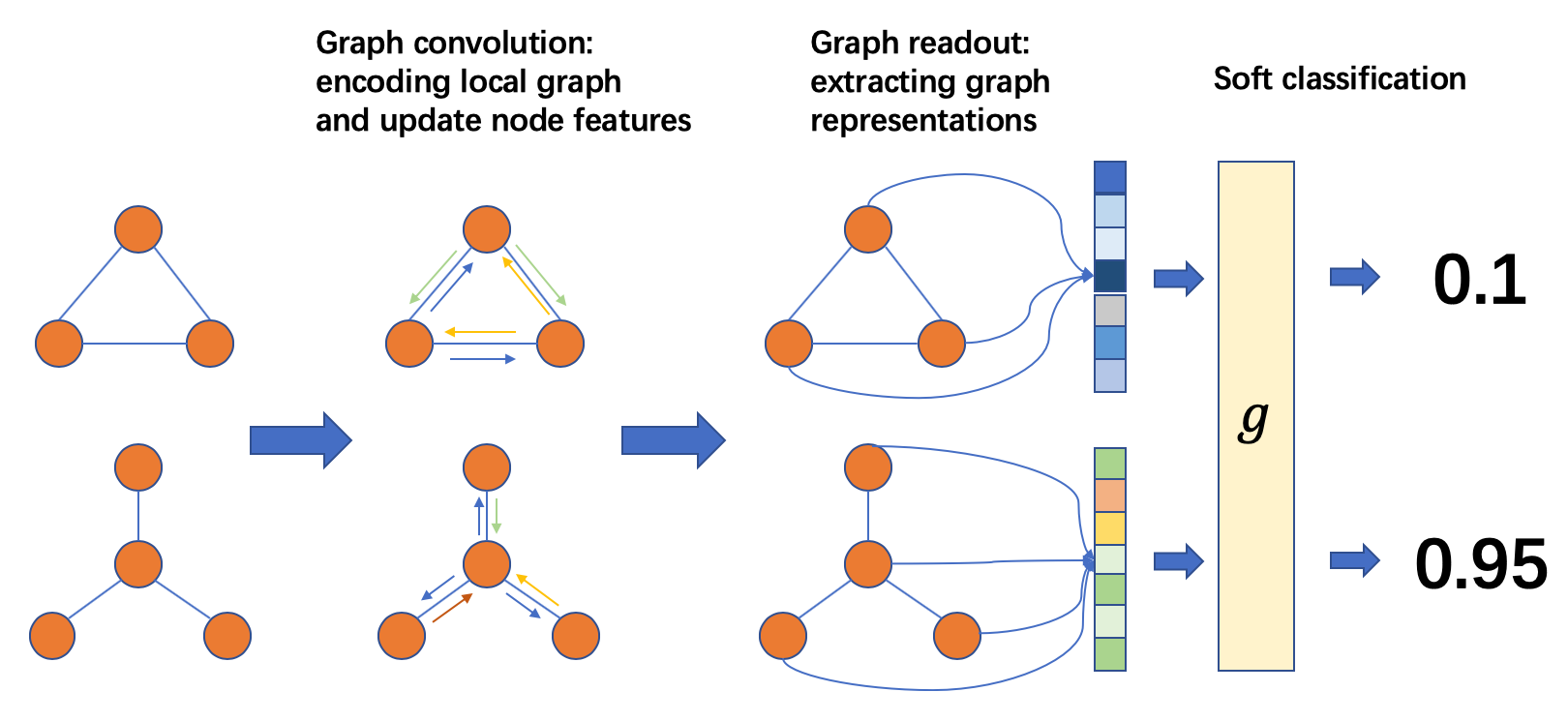
图分类流程
从左到右,常见的做法是
准备一批图
在批处理图上执行消息传递以更新节点/边特征
将节点/边特征聚合为图级别表示
根据图级别表示对图进行分类
图批处理
通常,图分类任务在很多图上进行训练,如果在训练模型时每次只使用一个图,效率会非常低。借鉴深度学习中 mini-batch 训练的思想,可以构建包含多个图的批处理,并将它们一起送入一个训练迭代。
在 DGL 中,可以从图列表中构建一个单独的批处理图。这个批处理图可以简单地用作一个大的图,其中的连通分量对应于原始的小图。
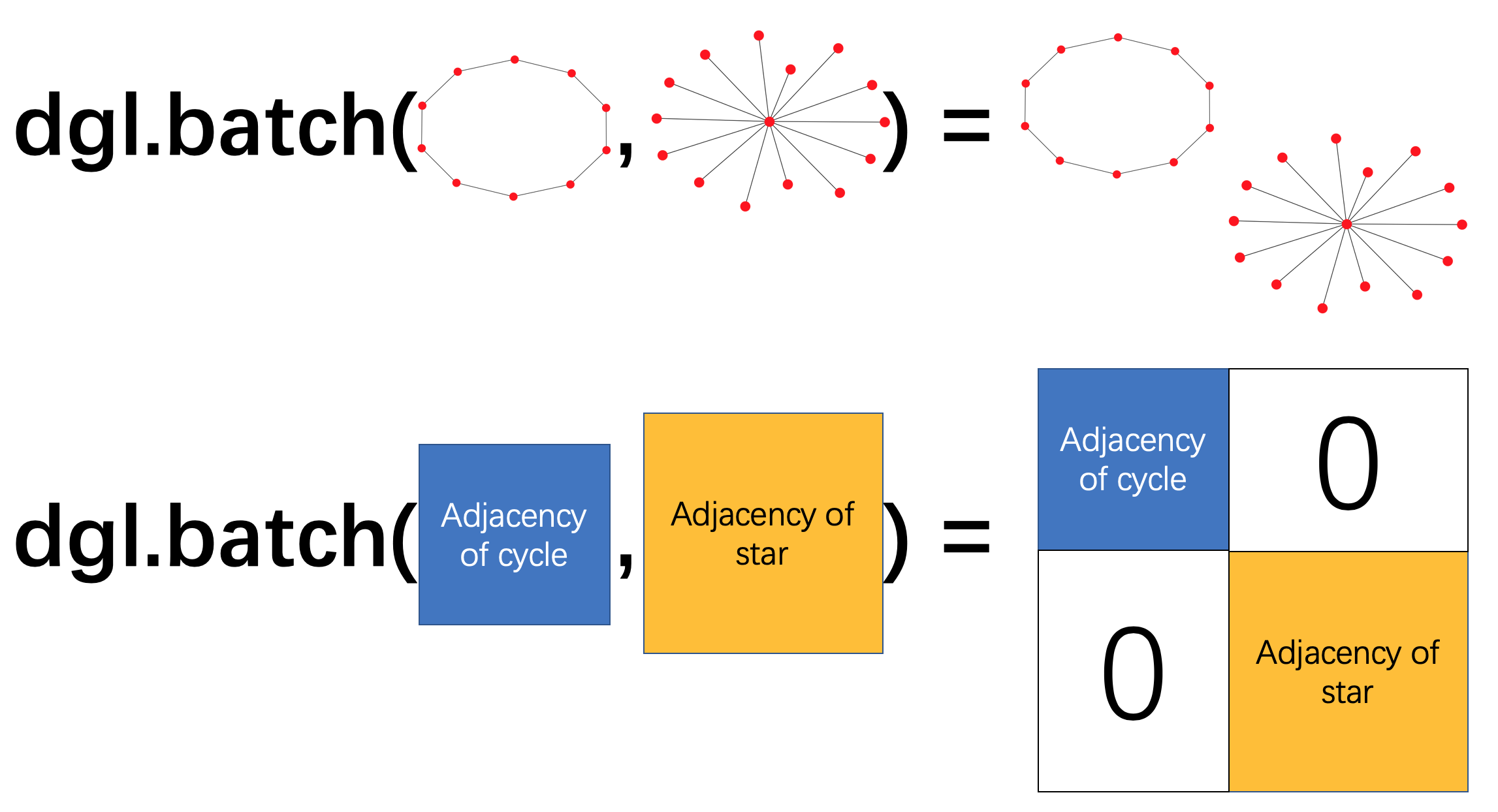
批处理图
以下示例对图列表调用了 dgl.batch()。批处理图是一个单一的图,但也包含了有关列表的信息。
import dgl
import torch as th
g1 = dgl.graph((th.tensor([0, 1, 2]), th.tensor([1, 2, 3])))
g2 = dgl.graph((th.tensor([0, 0, 0, 1]), th.tensor([0, 1, 2, 0])))
bg = dgl.batch([g1, g2])
bg
# Graph(num_nodes=7, num_edges=7,
# ndata_schemes={}
# edata_schemes={})
bg.batch_size
# 2
bg.batch_num_nodes()
# tensor([4, 3])
bg.batch_num_edges()
# tensor([3, 4])
bg.edges()
# (tensor([0, 1, 2, 4, 4, 4, 5], tensor([1, 2, 3, 4, 5, 6, 4]))
请注意,大多数 DGL 变换函数会丢弃批处理信息。为了保持这些信息,请在变换后的图上使用 dgl.DGLGraph.set_batch_num_nodes() 和 dgl.DGLGraph.set_batch_num_edges()。
图读出
数据中的每个图可能都有其独特的结构以及节点和边特征。为了进行单个预测,通常需要对这些可能丰富的信息进行聚合和汇总。这种操作被称为 readout(读出)。常见的读出操作包括对所有节点或边特征进行求和、平均、最大值或最小值。
给定一个图 \(g\),可以将节点特征的平均读出定义为
其中 \(h_g\) 是 \(g\) 的表示,\(\mathcal{V}\) 是 \(g\) 中的节点集合,\(h_v\) 是节点 \(v\) 的特征。
DGL 内置支持常见的读出操作。例如,dgl.mean_nodes() 实现了上述读出操作。
一旦 \(h_g\) 可用,就可以将其通过一个 MLP 层进行分类输出。
编写神经网络模型
模型的输入是带有节点和边特征的批处理图。
在批处理图上计算
首先,批处理中的不同图是完全分离的,即任意两个图之间没有边。有了这个很好的属性,所有的消息传递函数仍然会得到相同的结果。
其次,批处理图上的读出函数将分别对每个图进行。假设批处理大小为 \(B\),要聚合的特征维度为 \(D\),则读出结果的形状将是 \((B, D)\)。
import dgl
import torch
g1 = dgl.graph(([0, 1], [1, 0]))
g1.ndata['h'] = torch.tensor([1., 2.])
g2 = dgl.graph(([0, 1], [1, 2]))
g2.ndata['h'] = torch.tensor([1., 2., 3.])
dgl.readout_nodes(g1, 'h')
# tensor([3.]) # 1 + 2
bg = dgl.batch([g1, g2])
dgl.readout_nodes(bg, 'h')
# tensor([3., 6.]) # [1 + 2, 1 + 2 + 3]
最后,批处理图中的每个节点/边特征是通过按顺序连接所有图中的相应特征获得的。
bg.ndata['h']
# tensor([1., 2., 1., 2., 3.])
模型定义
了解了上述计算规则后,可以按如下方式定义模型。
import dgl.nn.pytorch as dglnn
import torch.nn as nn
class Classifier(nn.Module):
def __init__(self, in_dim, hidden_dim, n_classes):
super(Classifier, self).__init__()
self.conv1 = dglnn.GraphConv(in_dim, hidden_dim)
self.conv2 = dglnn.GraphConv(hidden_dim, hidden_dim)
self.classify = nn.Linear(hidden_dim, n_classes)
def forward(self, g, h):
# Apply graph convolution and activation.
h = F.relu(self.conv1(g, h))
h = F.relu(self.conv2(g, h))
with g.local_scope():
g.ndata['h'] = h
# Calculate graph representation by average readout.
hg = dgl.mean_nodes(g, 'h')
return self.classify(hg)
训练循环
数据加载
定义好模型后,就可以开始训练了。由于图分类处理的是许多相对较小的图,而不是一个大型图,因此可以在图的随机 mini-batches 上高效地进行训练,而无需设计复杂的图采样算法。
假设您有一个图分类数据集,如 第四章:图数据流水线 中介绍的。
import dgl.data
dataset = dgl.data.GINDataset('MUTAG', False)
图分类数据集中的每个项目都是图及其标签的对。可以利用 GraphDataLoader 加速数据加载过程,以 mini-batches 迭代图数据集。
from dgl.dataloading import GraphDataLoader
dataloader = GraphDataLoader(
dataset,
batch_size=1024,
drop_last=False,
shuffle=True)
训练循环然后只需迭代 dataloader 并更新模型即可。
import torch.nn.functional as F
# Only an example, 7 is the input feature size
model = Classifier(7, 20, 5)
opt = torch.optim.Adam(model.parameters())
for epoch in range(20):
for batched_graph, labels in dataloader:
feats = batched_graph.ndata['attr']
logits = model(batched_graph, feats)
loss = F.cross_entropy(logits, labels)
opt.zero_grad()
loss.backward()
opt.step()
有关图分类的端到端示例,请参阅 DGL 的 GIN 示例。训练循环位于 main.py 的函数 train 中。模型实现位于 gin.py 中,包含更多组件,例如使用 dgl.nn.pytorch.GINConv(MXNet 和 Tensorflow 中也可用)作为图卷积层、批归一化等。
异构图
异构图的图分类与同构图的图分类略有不同。除了与异构图兼容的图卷积模块外,在读出函数中还需要聚合不同类型的节点。
下面展示一个对每种节点类型的节点表示的平均值求和的示例。
class RGCN(nn.Module):
def __init__(self, in_feats, hid_feats, out_feats, rel_names):
super().__init__()
self.conv1 = dglnn.HeteroGraphConv({
rel: dglnn.GraphConv(in_feats, hid_feats)
for rel in rel_names}, aggregate='sum')
self.conv2 = dglnn.HeteroGraphConv({
rel: dglnn.GraphConv(hid_feats, out_feats)
for rel in rel_names}, aggregate='sum')
def forward(self, graph, inputs):
# inputs is features of nodes
h = self.conv1(graph, inputs)
h = {k: F.relu(v) for k, v in h.items()}
h = self.conv2(graph, h)
return h
class HeteroClassifier(nn.Module):
def __init__(self, in_dim, hidden_dim, n_classes, rel_names):
super().__init__()
self.rgcn = RGCN(in_dim, hidden_dim, hidden_dim, rel_names)
self.classify = nn.Linear(hidden_dim, n_classes)
def forward(self, g):
h = g.ndata['feat']
h = self.rgcn(g, h)
with g.local_scope():
g.ndata['h'] = h
# Calculate graph representation by average readout.
hg = 0
for ntype in g.ntypes:
hg = hg + dgl.mean_nodes(g, 'h', ntype=ntype)
return self.classify(hg)
其余代码与同构图的代码没有区别。
# etypes is the list of edge types as strings.
model = HeteroClassifier(10, 20, 5, etypes)
opt = torch.optim.Adam(model.parameters())
for epoch in range(20):
for batched_graph, labels in dataloader:
logits = model(batched_graph)
loss = F.cross_entropy(logits, labels)
opt.zero_grad()
loss.backward()
opt.step()