第七章: 分布式训练
注意
分布式训练仅适用于 PyTorch 后端。
DGL 采用完全分布式方法,将数据和计算分布到一组计算资源上。在本节中,我们将假设在一个集群环境中(即一组机器)。DGL 将一个图划分为子图,集群中的每台机器负责一个子图(分区)。DGL 在集群中的所有机器上运行相同的训练脚本以并行化计算,并在同一机器上运行服务器,将分区数据提供给训练器。
对于训练脚本,DGL 提供的分布式 API 与 mini-batch 训练的 API 类似。这使得分布式训练只需对单机 mini-batch 训练的代码进行少量修改。下面是一个分布式训练 GraphSage 的示例。值得注意的代码修改包括:1) 初始化 DGL 的分布式模块,2) 创建分布式图对象,以及 3) 划分训练集并计算本地进程所需的节点。代码的其余部分,包括采样器创建、模型定义、训练循环等,与mini-batch 训练相同。
import dgl
from dgl.dataloading import NeighborSampler
from dgl.distributed import DistGraph, DistDataLoader, node_split
import torch as th
# initialize distributed contexts
dgl.distributed.initialize('ip_config.txt')
th.distributed.init_process_group(backend='gloo')
# load distributed graph
g = DistGraph('graph_name', 'part_config.json')
pb = g.get_partition_book()
# get training workload, i.e., training node IDs
train_nid = node_split(g.ndata['train_mask'], pb, force_even=True)
# Create sampler
sampler = NeighborSampler(g, [10,25],
dgl.distributed.sample_neighbors,
device)
dataloader = DistDataLoader(
dataset=train_nid.numpy(),
batch_size=batch_size,
collate_fn=sampler.sample_blocks,
shuffle=True,
drop_last=False)
# Define model and optimizer
model = SAGE(in_feats, num_hidden, n_classes, num_layers, F.relu, dropout)
model = th.nn.parallel.DistributedDataParallel(model)
loss_fcn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=args.lr)
# training loop
for epoch in range(args.num_epochs):
with model.join():
for step, blocks in enumerate(dataloader):
batch_inputs, batch_labels = load_subtensor(g, blocks[0].srcdata[dgl.NID],
blocks[-1].dstdata[dgl.NID])
batch_pred = model(blocks, batch_inputs)
loss = loss_fcn(batch_pred, batch_labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
DGL 实现了一些分布式组件来支持分布式训练。下图展示了这些组件及其交互。
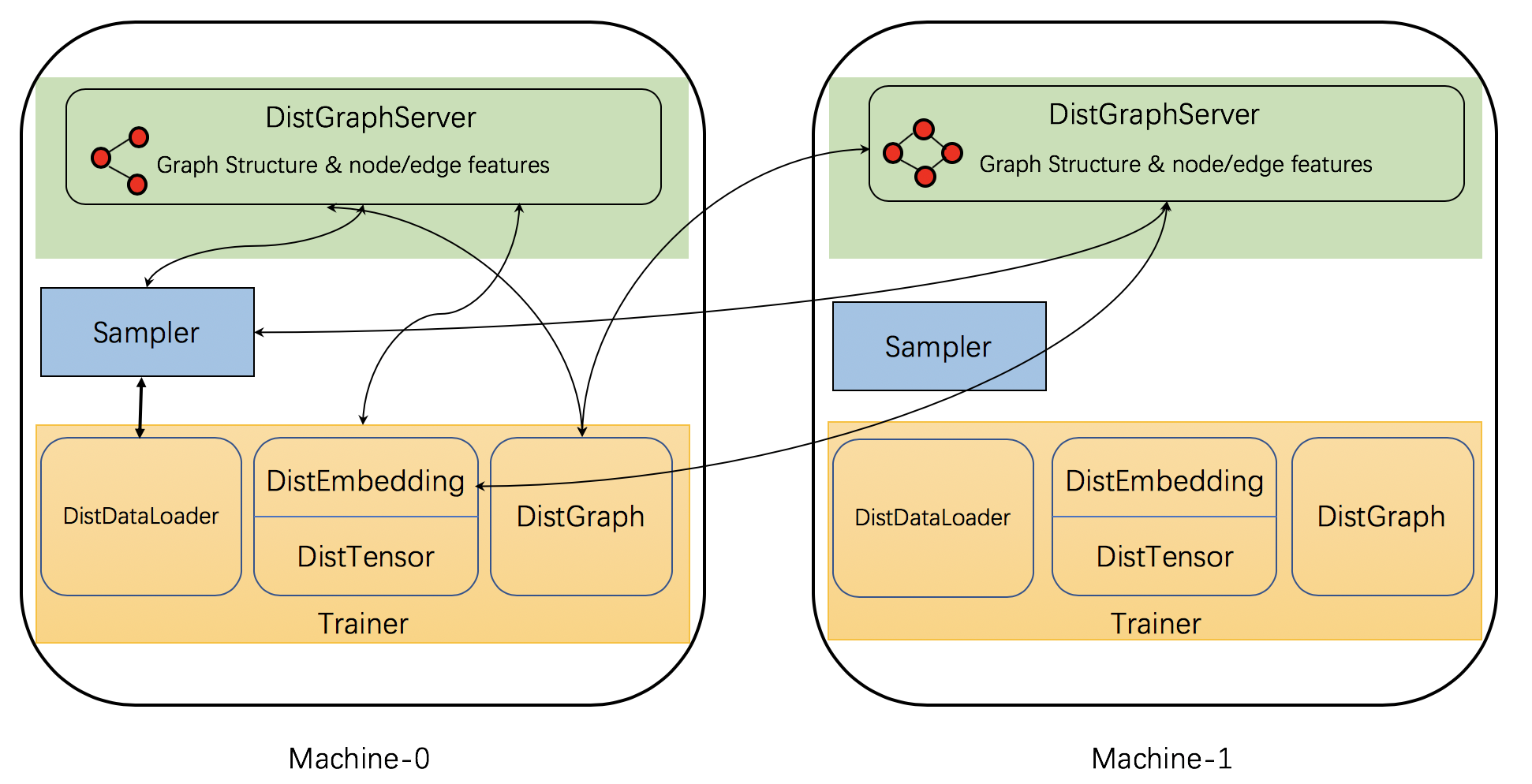
具体来说,DGL 的分布式训练有三种相互作用的进程类型:服务器 (server)、采样器 (sampler) 和 训练器 (trainer)。
服务器存储图分区,包括结构数据和节点/边特征。它们提供采样、获取或更新节点/边特征等服务。注意,每台机器可以同时运行多个服务器进程来增加服务吞吐量。其中一个是主服务器 (main server),负责数据加载并通过共享内存与提供服务的备份服务器 (backup servers) 共享数据。
采样器进程与服务器交互,采样节点和边,生成用于训练的 mini-batch。
训练器负责在 mini-batch 上训练网络。它们使用诸如
DistGraph来访问分区图数据,DistEmbedding和DistTensor来访问节点/边特征/嵌入,以及DistDataLoader与采样器交互以获取 mini-batch。训练器之间使用 PyTorch 原生的DistributedDataParallel范式来通信梯度。
除了 Python API,DGL 还提供工具,用于在整个集群中配置图数据和进程。
考虑到这些分布式组件,本节的其余部分将涵盖以下分布式组件
对于那些对更多细节感兴趣的高级用户