7.1 数据预处理
在启动训练任务之前,DGL 要求对输入数据进行分区并分发到目标机器。为了处理不同规模的图,DGL 提供了两种分区方法:
一种适用于单机内存可容纳的图的分区 API。
一种适用于超出单机容量的图的分布式分区管道。
7.1.1 分区 API
对于相对较小的图,DGL 提供了一个分区 API partition_graph(),用于对内存中的 DGLGraph 对象进行分区。它支持多种分区算法,例如随机分区和 Metis。Metis 分区的优势在于它可以生成具有最小边缘切割的分区,从而减少分布式训练和推理的网络通信。DGL 使用最新版本的 Metis,并针对真实世界中的幂律分布图进行了优化。分区后,该 API 会以易于在训练期间加载的格式构建分区结果。例如,
import dgl
g = ... # create or load a DGLGraph object
dgl.distributed.partition_graph(g, 'mygraph', 2, 'data_root_dir')
将输出以下数据文件。
data_root_dir/
|-- mygraph.json # metadata JSON. File name is the given graph name.
|-- part0/ # data for partition 0
| |-- node_feats.dgl # node features stored in binary format
| |-- edge_feats.dgl # edge features stored in binary format
| |-- graph.dgl # graph structure of this partition stored in binary format
|
|-- part1/ # data for partition 1
|-- node_feats.dgl
|-- edge_feats.dgl
|-- graph.dgl
章节 7.4 高级图分区 介绍了关于分区格式的更多细节。要将分区分发到集群,用户可以将数据保存在所有机器都可以访问的共享文件夹中,或者将元数据 JSON 以及相应的分区文件夹 partX 复制到第 X 台机器上。
使用 partition_graph() 需要一个具有足够大 CPU RAM 的实例来容纳整个图结构和特征,这对于拥有数千亿条边或大型特征的图可能不可行。接下来,我们将描述如何为此类情况使用并行数据准备管道。
负载均衡
默认情况下,在对图进行分区时,METIS 只平衡每个分区中的节点数量。根据具体任务,这可能会导致次优配置。例如,在半监督节点分类的情况下,训练器在本地分区中的标记节点子集上执行计算。如果只平衡图中的节点(包括标记和未标记),可能会导致计算负载不均衡。为了在每个分区中获得平衡的工作负载,分区 API 允许通过在 partition_graph() 中指定 balance_ntypes 来平衡各个分区中每种节点类型的节点数量。用户可以利用这一点,将训练集、验证集和测试集中的节点视为不同的节点类型。
以下示例将训练集内部的节点和训练集外部的节点视为两种节点类型
dgl.distributed.partition_graph(g, 'graph_name', 4, '/tmp/test', balance_ntypes=g.ndata['train_mask'])
除了平衡节点类型外,dgl.distributed.partition_graph() 还允许通过指定 balance_edges 来平衡不同节点类型的节点的入度。这平衡了连接到不同类型节点的边缘数量。
ID 映射
分区后,partition_graph() 会重新映射节点和边缘 ID,以便同一分区的节点排列在一起(在连续的 ID 范围),从而更容易存储分区的节点/边缘特征。该 API 还会根据新的 ID 自动打乱节点/边缘特征。然而,某些下游任务可能希望恢复原始的节点/边缘 ID(例如,提取计算出的节点嵌入以供后续使用)。对于这种情况,请将 return_mapping=True 传递给 partition_graph(),这会使 API 返回重新映射的节点/边缘 ID 与其原始 ID 之间的映射。对于同构图,它返回两个向量。第一个向量将每个新节点 ID 映射到其原始 ID;第二个向量将每个新边缘 ID 映射到其原始 ID。对于异构图,它返回两个向量字典。第一个字典包含每种节点类型的映射;第二个字典包含每种边缘类型的映射。
node_map, edge_map = dgl.distributed.partition_graph(g, 'graph_name', 4, '/tmp/test',
balance_ntypes=g.ndata['train_mask'],
return_mapping=True)
# Let's assume that node_emb is saved from the distributed training.
orig_node_emb = th.zeros(node_emb.shape, dtype=node_emb.dtype)
orig_node_emb[node_map] = node_emb
加载已分区的图
DGL 提供了一个 dgl.distributed.load_partition() 函数来加载一个分区进行检查。
>>> import dgl
>>> # load partition 0
>>> part_data = dgl.distributed.load_partition('data_root_dir/graph_name.json', 0)
>>> g, nfeat, efeat, partition_book, graph_name, ntypes, etypes = part_data # unpack
>>> print(g)
Graph(num_nodes=966043, num_edges=34270118,
ndata_schemes={'orig_id': Scheme(shape=(), dtype=torch.int64),
'part_id': Scheme(shape=(), dtype=torch.int64),
'_ID': Scheme(shape=(), dtype=torch.int64),
'inner_node': Scheme(shape=(), dtype=torch.int32)}
edata_schemes={'_ID': Scheme(shape=(), dtype=torch.int64),
'inner_edge': Scheme(shape=(), dtype=torch.int8),
'orig_id': Scheme(shape=(), dtype=torch.int64)})
如ID 映射部分所述,每个分区都携带有辅助信息,作为 ndata 或 edata 保存,例如原始节点/边缘 ID、分区 ID 等。每个分区不仅保存它拥有的节点/边缘,还包括与该分区相邻的节点/边缘(称为 HALO 节点/边缘)。inner_node 和 inner_edge 指示节点/边缘是否真正属于该分区(值为 True)或是一个 HALO 节点/边缘(值为 False)。
加载已分区的图load_partition() 函数一次性加载所有数据。用户可以使用 dgl.distributed.load_partition_feats() 和 dgl.distributed.load_partition_book() API 分别加载特征或分区簿。
7.1.2 分布式图分区管道
为了处理无法放入单机 CPU RAM 的海量图数据,DGL 利用数据分块和并行处理来减少内存占用和运行时间。下图说明了该管道
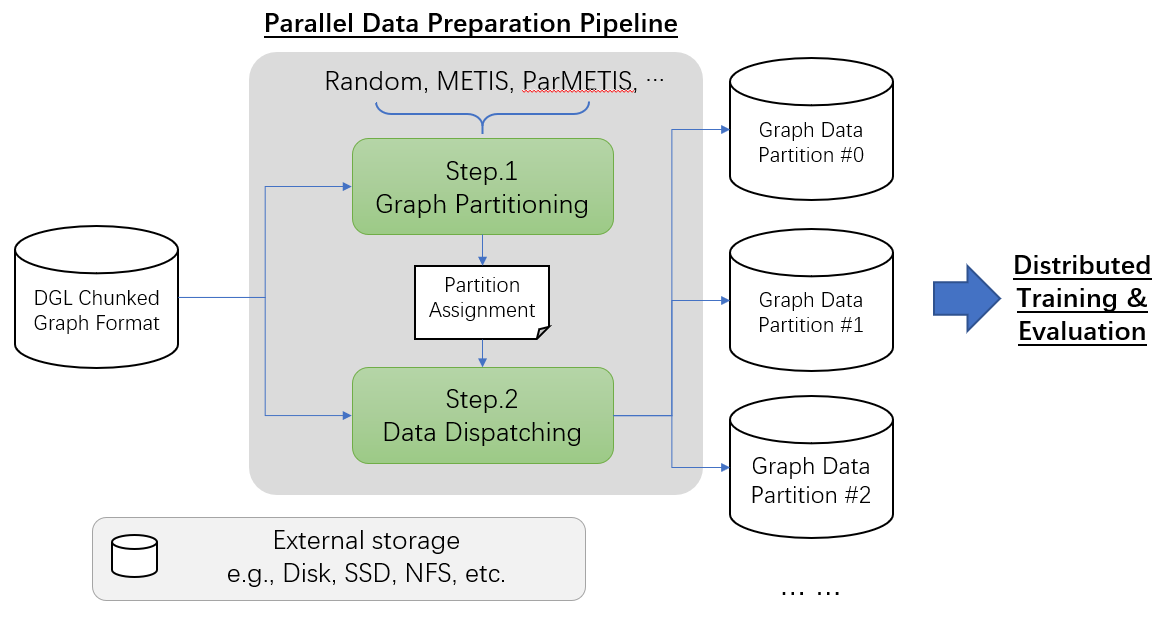
该管道接收存储在分块图格式中的输入数据,并生成数据分区并分发到目标机器。
步骤 1:图分区:计算每个分区的归属权,并将结果保存为一组文件,称为分区分配。为了加速该步骤,一些算法(例如 ParMETIS)支持使用多台机器进行并行计算。
步骤 2:数据分发:给定分区分配,该步骤将实际对图数据进行分区,并将其分发到用户指定的机器。它还将图数据转换为适合分布式训练和评估的格式。
整个管道是模块化的,因此每个步骤都可以单独调用。例如,用户可以用一些自定义的图分区算法替换步骤 1,只要它能正确生成分区分配文件即可。
分块图格式
为了运行该管道,DGL 要求输入图存储在多个数据块中。每个数据块是数据预处理的单元,因此应该能够放入 CPU RAM。在本节中,我们以来自 Open Graph Benchmark 的 MAG240M-LSC 数据为例,描述整体设计,然后是正式规范以及创建这种格式数据的技巧。
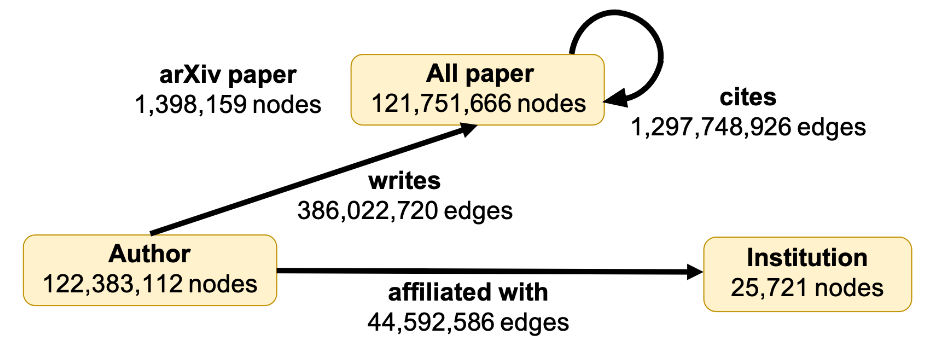
示例:MAG240M-LSC
MAG240M-LSC 图是一个从 Microsoft Academic Graph (MAG) 中提取的异构学术图,其模式图如下所示
其原始数据文件组织如下
/mydata/MAG240M-LSC/
|-- meta.pt # # A dictionary of the number of nodes for each type saved by torch.save,
| # as well as num_classes
|-- processed/
|-- author___affiliated_with___institution/
| |-- edge_index.npy # graph, 713 MB
|
|-- paper/
| |-- node_feat.npy # feature, 187 GB, (numpy memmap format)
| |-- node_label.npy # label, 974 MB
| |-- node_year.npy # year, 974 MB
|
|-- paper___cites___paper/
| |-- edge_index.npy # graph, 21 GB
|
|-- author___writes___paper/
|-- edge_index.npy # graph, 6GB
该图有三种节点类型("paper"、"author" 和 "institution"),三种边缘类型/关系("cites"、"writes" 和 "affiliated_with")。"paper" 节点有三个属性("feat"、"label"、"year"'),而其他类型的节点和边缘没有特征。下面显示了当它存储在 DGL 分块图格式中的数据文件
/mydata/MAG240M-LSC_chunked/
|-- metadata.json # metadata json file
|-- edges/ # stores edge ID data
| |-- writes-part1.csv
| |-- writes-part2.csv
| |-- affiliated_with-part1.csv
| |-- affiliated_with-part2.csv
| |-- cites-part1.csv
| |-- cites-part1.csv
|
|-- node_data/ # stores node feature data
|-- paper-feat-part1.npy
|-- paper-feat-part2.npy
|-- paper-label-part1.npy
|-- paper-label-part2.npy
|-- paper-year-part1.npy
|-- paper-year-part2.npy
所有数据文件都被分块为两部分,包括每种关系(例如 writes、affiliates、cites)的边缘和节点特征。如果图有边缘特征,它们也将被分块到多个文件中。所有 ID 数据都存储在 CSV 文件中(我们稍后将说明内容),而节点特征存储在 numpy 数组中。
文件 metadata.json 存储所有元数据信息,例如文件名和数据块大小(例如,节点数量、边缘数量)。
{
"graph_name" : "MAG240M-LSC", # given graph name
"node_type": ["author", "paper", "institution"],
"num_nodes_per_chunk": [
[61191556, 61191556], # number of author nodes per chunk
[61191553, 61191552], # number of paper nodes per chunk
[12861, 12860] # number of institution nodes per chunk
],
# The edge type name is a colon-joined string of source, edge, and destination type.
"edge_type": [
"author:writes:paper",
"author:affiliated_with:institution",
"paper:cites:paper"
],
"num_edges_per_chunk": [
[193011360, 193011360], # number of author:writes:paper edges per chunk
[22296293, 22296293], # number of author:affiliated_with:institution edges per chunk
[648874463, 648874463] # number of paper:cites:paper edges per chunk
],
"edges" : {
"author:writes:paper" : { # edge type
"format" : {"name": "csv", "delimiter": " "},
# The list of paths. Can be relative or absolute.
"data" : ["edges/writes-part1.csv", "edges/writes-part2.csv"]
},
"author:affiliated_with:institution" : {
"format" : {"name": "csv", "delimiter": " "},
"data" : ["edges/affiliated_with-part1.csv", "edges/affiliated_with-part2.csv"]
},
"paper:cites:paper" : {
"format" : {"name": "csv", "delimiter": " "},
"data" : ["edges/cites-part1.csv", "edges/cites-part2.csv"]
}
},
"node_data" : {
"paper": { # node type
"feat": { # feature key
"format": {"name": "numpy"},
"data": ["node_data/paper-feat-part1.npy", "node_data/paper-feat-part2.npy"]
},
"label": { # feature key
"format": {"name": "numpy"},
"data": ["node_data/paper-label-part1.npy", "node_data/paper-label-part2.npy"]
},
"year": { # feature key
"format": {"name": "numpy"},
"data": ["node_data/paper-year-part1.npy", "node_data/paper-year-part2.npy"]
}
}
},
"edge_data" : {} # MAG240M-LSC does not have edge features
}
文件 metadata.json 包含三部分
图模式信息和数据块大小,例如
"node_type"、"num_nodes_per_chunk"等。键
"edges"下的边缘索引数据。键
"node_data"和"edge_data"下的节点/边缘特征数据。
边缘索引文件包含以节点 ID 对形式存储的边缘
# writes-part1.csv
0 0
0 1
0 20
0 29
0 1203
...
规范
一般来说,分块图数据文件夹只需要一个 metadata.json 和一些数据文件。MAG240M-LSC 示例中的文件夹结构不是严格要求,只要 metadata.json 包含有效的文件路径即可。
metadata.json 顶层键
graph_name: String。由dgl.distributed.DistGraph用于加载图的唯一名称。node_type: String 列表。节点类型名称。num_nodes_per_chunk: 整数列表的列表。对于存储在 \(P\) 个数据块中的 \(T\) 种节点类型的图,该值包含 \(T\) 个整数列表。每个列表包含 \(P\) 个整数,指定每个数据块中的节点数量。edge_type: String 列表。边缘类型名称,格式为<source node type>:<relation>:<destination node type>。num_edges_per_chunk: 整数列表的列表。对于存储在 \(P\) 个数据块中的 \(R\) 种边缘类型的图,该值包含 \(R\) 个整数列表。每个列表包含 \(P\) 个整数,指定每个数据块中的边缘数量。edges:ChunkFileSpec字典。边缘索引文件。字典键是格式为<source node type>:<relation>:<destination node type>的边缘类型名称。node_data:ChunkFileSpec字典。存储节点属性的数据文件可以有任意数量的文件,与num_parts无关。字典键是节点类型名称。edge_data:ChunkFileSpec字典。存储边缘属性的数据文件可以有任意数量的文件,与num_parts无关。字典键是格式为<source node type>:<relation>:<destination node type>的边缘类型名称。
ChunkFileSpec 有两个键
format: 文件格式。根据格式name,用户可以配置如何解析每个数据文件的更多细节。"csv": CSV 文件。使用delimiter键指定所使用的分隔符。"numpy": 由numpy.save()创建的 NumPy 数组二进制文件。"parquet": 由pyarrow.parquet.write_table()创建的 parquet 表二进制文件。
data: String 列表。每个数据块的文件路径。支持绝对路径。
创建分块图数据的技巧
根据原始数据,实现可能包括
从非结构化数据(如文本或表格数据)构建图。
增强或转换输入图结构或特征。例如,添加反向或自环边缘,归一化特征等。
将输入图结构和特征分块为多个数据文件,以便每个文件都能放入 CPU RAM,用于后续的预处理步骤。
为了避免出现内存不足错误,建议分别处理图结构和特征数据。一次处理一个数据块也可以减少最大的运行时内存占用。例如,DGL 提供了一个 tools/chunk_graph.py 脚本,用于对内存中的无特征 DGLGraph 以及存储在 numpy.memmap 中的特征张量进行分块。
步骤 1:图分区
该步骤读取分块图数据并计算每个节点应属于哪个分区。结果保存在一组分区分配文件中。例如,要将 MAG240M-LSC 随机分区为两部分,请运行 tools 文件夹中的 partition_algo/random_partition.py 脚本
python /my/repo/dgl/tools/partition_algo/random_partition.py
--in_dir /mydata/MAG240M-LSC_chunked
--out_dir /mydata/MAG240M-LSC_2parts
--num_partitions 2
,其输出文件如下
MAG240M-LSC_2parts/
|-- paper.txt
|-- author.txt
|-- institution.txt
每个文件存储相应节点类型的分区分配。内容是以行存储的每个节点的区 ID,即第 i 行是节点 i 的分区 ID。
# paper.txt
0
1
1
0
0
1
0
...
尽管简单,随机分区可能导致频繁的跨机器通信。请查看章节 7.4 高级图分区 以获取更多高级选项。
步骤 2:数据分发
DGL 提供了一个 dispatch_data.py 脚本,用于实际对数据进行分区并将分区分发到每台训练机器。它还会再次将数据转换为可以由 DGL 训练进程高效加载的数据对象。整个步骤可以使用多进程进一步加速。
python /myrepo/dgl/tools/dispatch_data.py \
--in-dir /mydata/MAG240M-LSC_chunked/ \
--partitions-dir /mydata/MAG240M-LSC_2parts/ \
--out-dir data/MAG_LSC_partitioned \
--ip-config ip_config.txt
--in-dir指定输入分块图数据文件夹的路径--partitions-dir指定步骤 1 生成的分区分配文件夹的路径。--out-dir指定在每台机器上存储数据分区的路径。--ip-config指定集群的 IP 配置文件。
IP 配置文件的示例如下
172.31.19.1
172.31.23.205
作为 partition_graph() 中 return_mapping=True 的对应部分,分布式分区管道 在 dispatch_data.py 中提供了两个参数,用于将原始节点/边缘 ID 保存到磁盘。
--save-orig-nids将原始节点 ID 保存到文件。--save-orig-eids将原始边缘 ID 保存到文件。
指定这两个选项将在每个分区文件夹下创建两个文件:orig_nids.dgl 和 orig_eids.dgl。
data_root_dir/
|-- graph_name.json # partition configuration file in JSON
|-- part0/ # data for partition 0
| |-- orig_nids.dgl # original node IDs
| |-- orig_eids.dgl # original edge IDs
| |-- ... # other data such as graph and node/edge feats
|
|-- part1/ # data for partition 1
| |-- orig_nids.dgl
| |-- orig_eids.dgl
| |-- ...
|
|-- ... # data for other partitions
这两个文件将原始 ID 存储为张量字典,其中键是节点/边缘类型名称,值是 ID 张量。用户可以使用 dgl.data.load_tensors() 工具加载它们
# Load the original IDs for the nodes in partition 0.
orig_nids_0 = dgl.data.load_tensors('/path/to/data/part0/orig_nids.dgl')
# Get the original node IDs for node type 'user'
user_orig_nids_0 = orig_nids_0['user']
# Load the original IDs for the edges in partition 0.
orig_eids_0 = dgl.data.load_tensors('/path/to/data/part0/orig_eids.dgl')
# Get the original edge IDs for edge type 'like'
like_orig_eids_0 = orig_nids_0['like']
在数据分发期间,DGL 假设集群的总 CPU RAM 能够容纳整个图数据。节点的归属由分区算法的结果决定,而对于边缘,目标节点的归属者也拥有该边缘。