第六章:大规模图上的随机训练
如果我们有一个包含数百万甚至数十亿节点或边的庞大图,通常第五章:训练图神经网络中所述的全图训练将无法奏效。考虑一个在具有 \(N\) 个节点的图上运行的 \(L\) 层图卷积网络,其隐藏状态大小为 \(H\)。存储中间隐藏状态需要 \(O(NLH)\) 的内存,在 \(N\) 很大时很容易超出单个 GPU 的容量。
本节提供了一种执行随机 mini-batch 训练的方法,我们无需将所有节点的特征都载入到 GPU 中。
邻居采样方法概述
邻居采样方法通常按以下方式工作。对于每个梯度下降步骤,我们选择一个 mini-batch 的节点,计算它们在第 \(L\) 层上的最终表示。然后,我们在第 \(L-1\) 层获取它们全部或部分邻居。这个过程持续进行,直到我们到达输入层。如下图所示,这个迭代过程从输出层开始,向后工作到输入层,构建了依赖关系图
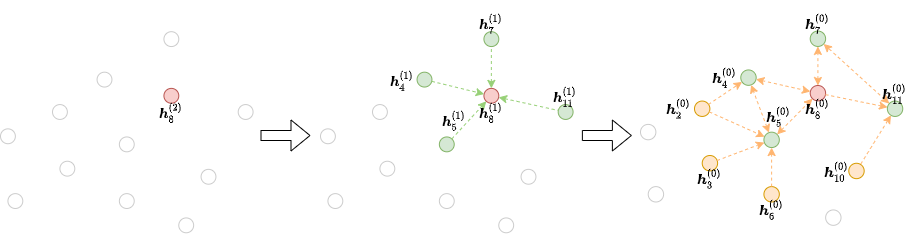
通过这种方式,可以节省在大规模图上训练 GNN 的工作量和计算资源。
DGL 提供了一些邻居采样器以及使用邻居采样训练 GNN 的流水线,同时还提供了自定义采样策略的方法。
路线图
本章首先介绍了在不同场景下对 GNN 进行随机训练的章节。
其余章节涵盖更高级的主题,适用于希望开发新的采样算法、与 mini-batch 训练兼容的新 GNN 模块,以及了解如何在 mini-batch 中进行评估和推理的用户。
以下是实现和使用邻居采样的性能提示