4.1 DGLDataset 类
DGLDataset 是定义在 dgl.data 中的图数据集处理、加载和保存的基础类。它实现了处理图数据的基本流水线。下面的流程图展示了该流水线的工作原理。
要处理位于远程服务器或本地磁盘中的图数据集,可以定义一个类,例如 MyDataset,继承自 dgl.data.DGLDataset。MyDataset 的模板如下所示。
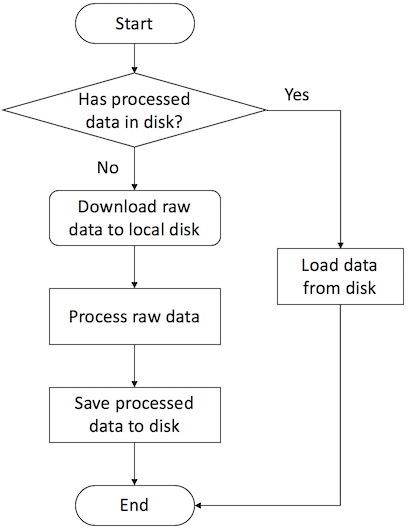
类 DGLDataset 中定义的图数据输入流水线的流程图。
from dgl.data import DGLDataset
class MyDataset(DGLDataset):
""" Template for customizing graph datasets in DGL.
Parameters
----------
url : str
URL to download the raw dataset
raw_dir : str
Specifying the directory that will store the
downloaded data or the directory that
already stores the input data.
Default: ~/.dgl/
save_dir : str
Directory to save the processed dataset.
Default: the value of `raw_dir`
force_reload : bool
Whether to reload the dataset. Default: False
verbose : bool
Whether to print out progress information
"""
def __init__(self,
url=None,
raw_dir=None,
save_dir=None,
force_reload=False,
verbose=False):
super(MyDataset, self).__init__(name='dataset_name',
url=url,
raw_dir=raw_dir,
save_dir=save_dir,
force_reload=force_reload,
verbose=verbose)
def download(self):
# download raw data to local disk
pass
def process(self):
# process raw data to graphs, labels, splitting masks
pass
def __getitem__(self, idx):
# get one example by index
pass
def __len__(self):
# number of data examples
pass
def save(self):
# save processed data to directory `self.save_path`
pass
def load(self):
# load processed data from directory `self.save_path`
pass
def has_cache(self):
# check whether there are processed data in `self.save_path`
pass
DGLDataset 类包含必须在子类中实现的抽象函数 process()、__getitem__(idx) 和 __len__()。DGL 还建议实现保存和加载功能,因为它们可以为处理大型数据集节省大量时间,并且有一些 API 可以使其变得容易(参见 4.4 保存和加载数据)。
请注意,DGLDataset 的目的是提供一种标准且方便的方式来加载图数据。可以在其中存储图、特征、标签、掩码以及数据集的基本信息,例如类别数、标签数等。采样、划分或特征归一化等操作是在 DGLDataset 子类之外完成的。
本章的其余部分将展示实现流水线中函数的最佳实践。