
DGL 2.1:为您的 GNN 数据流水线带来 GPU 加速
我们很高兴宣布 DGL 2.1 版本发布。在此版本中,我们让 GNN 数据加载速度变得极快。我们在 GraphBolt 中为整个 GNN 数据加载流水线引入了 GPU 加速,包括图采样和特征获取阶段。
灵活的数据流水线 & 可定制的阶段,全部在您的 GPU 上加速
从这个版本开始,数据移动阶段现在可以提前到数据流水线中,以实现 GPU 加速。考虑到这一点,现在核心阶段可以进行以下排列组合
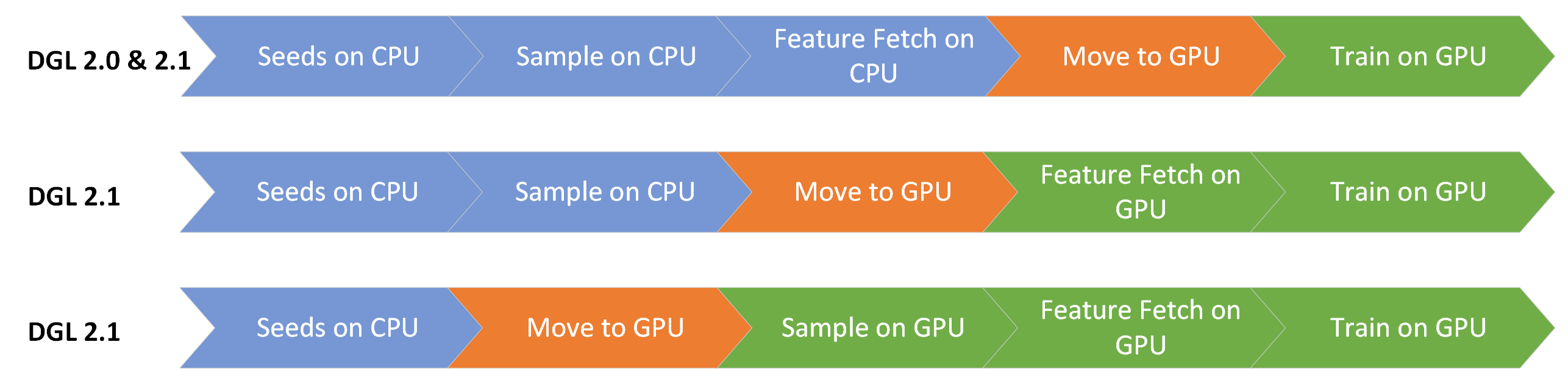
要在 GPU 上执行所有数据加载阶段,图和特征需要可被 GPU 访问。由于 GPU 内存可能有限,GraphBolt 提供就地 pinning 操作,以使驻留在主内存中的图和特征可以被 GPU 访问。
# Pin the graph and features in-place.
graph = dataset.graph.pin_memory_()
features = dataset.feature.pin_memory_()
然而,如果 GPU 有足够的内存,可以将图和/或其特征移动到 GPU,如下所示
# Move the graph and features to the GPU.
graph = dataset.graph.to("cuda:0")
features = dataset.feature.to("cuda:0")
如果 GPU 内存很大,但可能不足以容纳所有特征,在这种情况下,可以使用 gb.GPUCachedFeature 缓存部分特征,请参阅GraphBolt 多 GPU 示例。
通过将复制操作提前到流水线中,可以实现其余操作的 GPU 执行。所有 GraphBolt 组件的组合都符合您的预期。
# Seed edge sampler.
dp = gb.ItemSampler(train_edge_set, batch_size=1024, shuffle=True)
# Copy here to execute the remaining operations on the GPU.
dp = dp.copy_to(device="cuda:0")
# Negative sampling.
dp = dp.sample_uniform_negative(graph, negative_ratio=10)
# Neighbor sampling.
dp = dp.sample_neighbor(graph, fanouts=[15, 10, 5])
# Fetch features.
dp = dp.fetch_feature(features, node_feature_keys=["feat"])
PyTorch datapipe 的描述性特性使我们能够采用定义好的数据流水线,对其进行修改以支持 GPU 特定的优化,而不会改变用户体验。两个这样的例子是 gb.DataLoader 的 overlap_feature_fetch 和 overlap_graph_fetch 参数,其中特征获取和图访问操作通过管道并行使用单独的 CUDA 流与其余操作重叠。
GPU 加速带来的性能提升
dgl.graphbolt 不仅为您提供了灵活性,还在底层提供了顶级的性能。在 2.1 版本中,除了带放回采样之外,几乎所有 dgl.graphbolt 操作都已实现 GPU 加速。此外,特征获取操作现在通过管道并行与所有其他操作并行运行。根据具体场景,这有可能将运行时缩短至多 2 倍。而且,利用 gb.GPUCachedFeature 可以进一步缩短特征传输时间,我们的多 GPU 基准测试显示速度提升高达 1.6 倍。
为了评估 GraphBolt 的性能,我们测试了 4 种不同的场景
- 单 GPU 节点分类
- 单 GPU 链接预测
- 单 GPU 异构节点分类
- 多 GPU 节点分类
在这些场景中,我们将比较 5 种不同的配置。前两种是现有的基准配置,后三种是 DGL 2.1 版本新增的配置
- GraphBolt CPU 后端,表示为“dgl.graphbolt (cpu)”。
- 利用 GPU 上的 UVA 的传统 DGL 数据加载器,通过将数据集固定在系统内存中,表示为“Legacy DGL (pinned)”。
- GraphBolt GPU 后端,通过将数据集固定在系统内存中,表示为“dgl.graphbolt (pinned)”。
- GraphBolt GPU 后端,通过将数据集固定在系统内存中,并利用 gb.GPUCachedFeature 缓存 5M 个节点特征,表示为“dgl.graphbolt (pinned, 5M)”。
- GraphBolt GPU 后端,通过将数据集移动到 GPU 内存中,表示为“dgl.graphbolt (cuda)”。
所有实验均在配备 8 个 GPU 的 NVIDIA DGX-A100 系统上运行。
单 GPU 节点分类
我们评估了当数据集存储在固定内存 (UVA) 中时,GraphBolt 和传统 DGL 数据加载器相对于 CPU GraphBolt 基准的性能。我们使用具有 3 层的 GraphSage 模型,每层批大小为 1024,fanout 为 10,并使用上述列出的基准在 ogbn-products 和 ogbn-papers100M 数据集上评估性能。
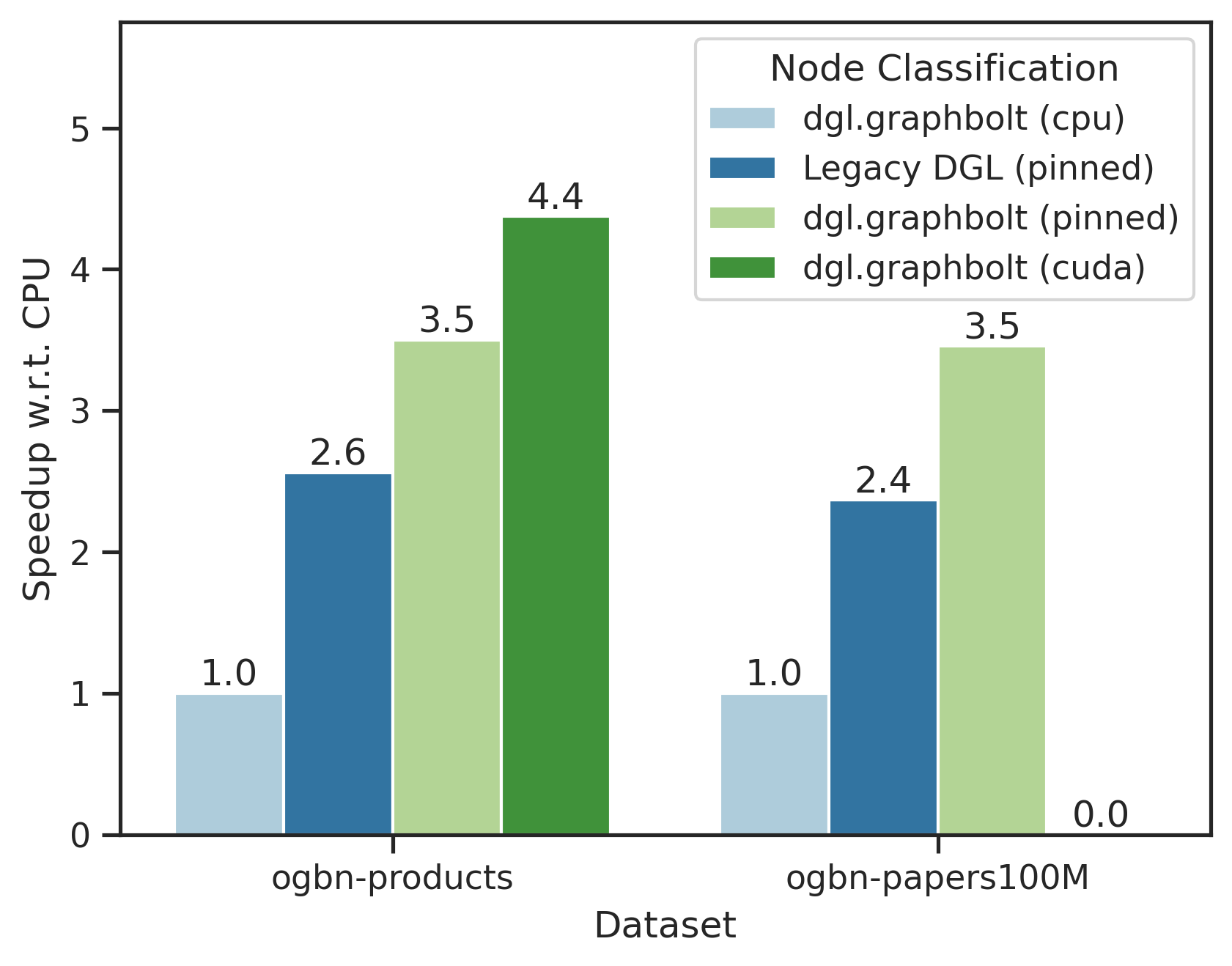
可以看出,GraphBolt 的新 GPU 后端相比 GraphBolt CPU 基准可获得高达 4.2 倍的加速,而传统 DGL 数据加载器至多获得 2.5 倍的加速。
单 GPU 链接预测
在这里,我们将重点转向 ogbl-citation2 数据集上的链接预测场景,设置与上一节类似。这里评估了两种不同的模式,包括或不包括反向边。
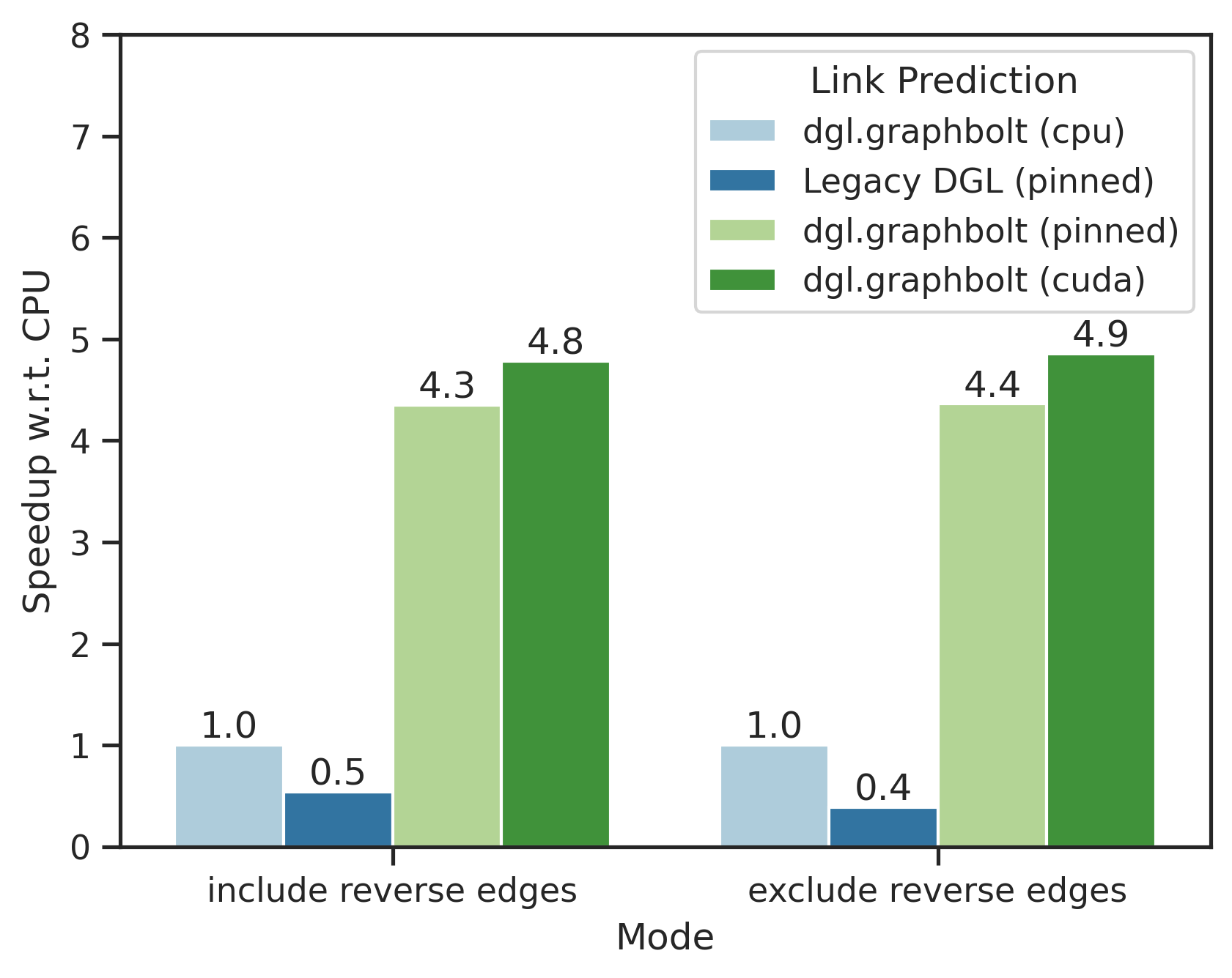
我们观察到,GraphBolt 的新 GPU 后端相比其 CPU 基准可获得高达 5 倍的加速。传统 DGL 数据加载器速度较慢,因为缺少链接预测数据加载所需的部分操作的 GPU 实现。
单 GPU 异构节点分类
您也可以在 GPU 上加速异构采样。R-GCN 示例在 ogbn-mag 数据集上的运行时,使用“dgl.graphbolt (cpu)”基准为 43.5 秒,而使用新的“dgl.graphbolt (pinned)”则降至 25.2 秒,获得了 1.73 倍的加速。随着我们针对不同的 GPU 用例进行优化,您可以期待加速效果进一步提升。
多 GPU 节点分类
在这里,我们评估了在多 GPU 环境下,使用 GraphSage 模型在 ogbn-papers100M 数据集(1.11 亿节点和 32 亿边)上的节点分类用例。设置与单 GPU 场景类似,不同之处在于每个 GPU 使用 1024 的批大小,而全局批大小随着 GPU 数量线性增加。
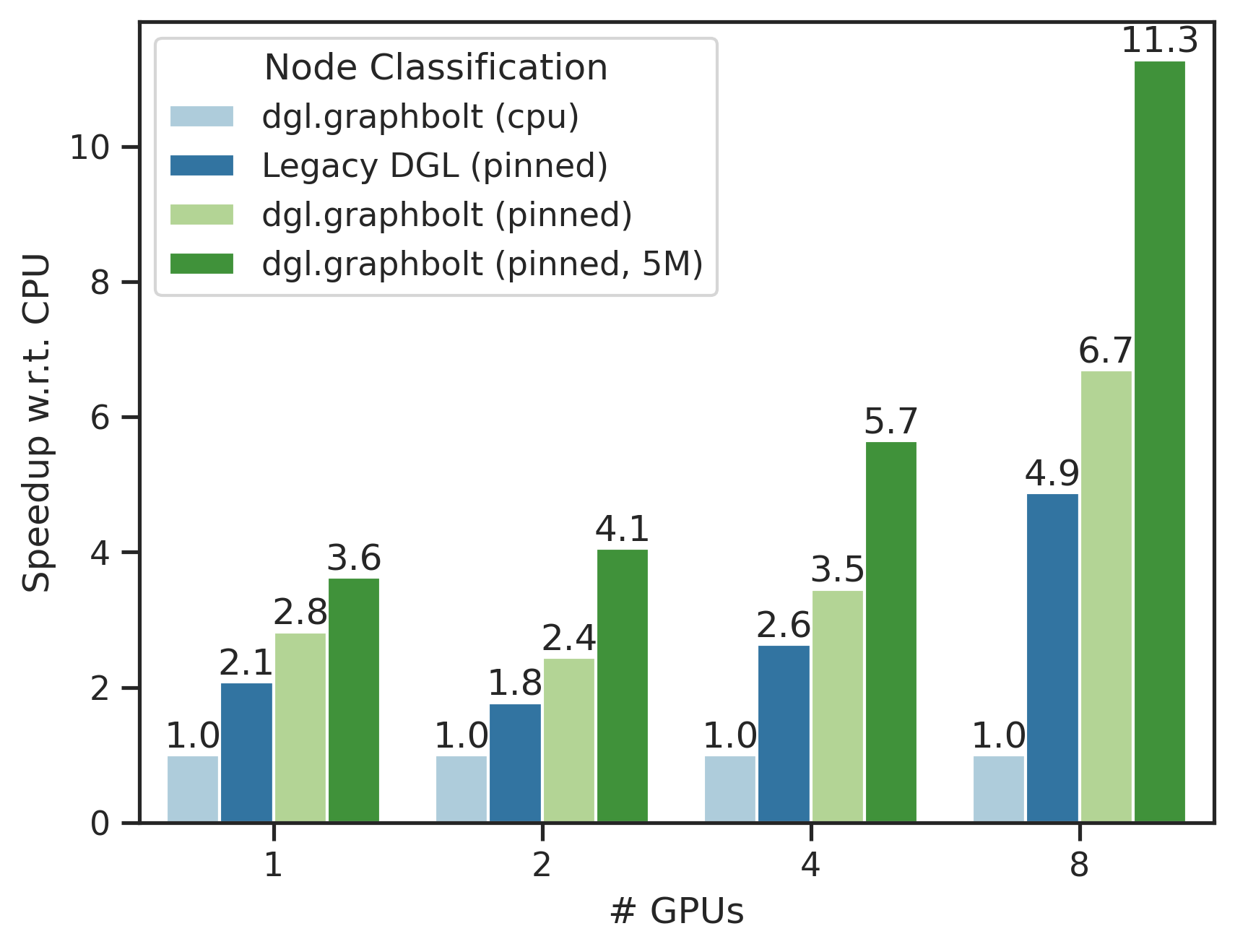
我们的每块 A100 GPU 上的 40GB 内存都可以被 GraphBolt 的 GPU 缓存功能利用。相比于之前的最先进基准,Legacy DGL (pinned),我们在单 GPU 上实现了 1.75 倍的提升,在 8 个 GPU 上实现了 2.31 倍的提升。此外,与 GraphBolt CPU 基准相比,我们实现了超过 10 倍的提升。
降低图存储空间需求
许多大规模图和现有 GNN 数据集的节点数少于 20 亿,但边数超过 20 亿。一个这样的例子是 ogbn-papers100M 图,它有 1.11 亿个节点和 32 亿条边。dgl.graphbolt 使用 CSC (Compressed Sparse Column) 格式以内存高效的方式存储您的图。通过我们最新的改进,现在内存使用量与边数相关,每条边占 4 字节 (int32),与节点数相关,每个节点占 8 字节 (int64),这意味着通过使用混合数据类型,图存储空间节省了近 2 倍。所提供的预处理功能会自动将数据集中的张量转换为最小的数据类型,以实现最佳空间利用和性能,例如异构情况下的边类型信息。通过这些优化,与我们之前的版本相比,异构 ogb-lsc-mag240m 图的空间节省了 3 倍。
更多内容
此外,dgl.graphbolt 也兼容 PyTorch Geometric。在下图中,括号中的表示图和特征的放置位置。“(cpu-cuda)”表示图放置在 CPU 上,而特征移动到 GPU 上。我们将我们的 高级 PyG 示例 与 PyG 官方示例进行比较,两者都使用 PyG GraphSAGE 模型。我们在 ogbn-products 数据集上运行节点分类任务,fanout 为 [15, 10, 5]。
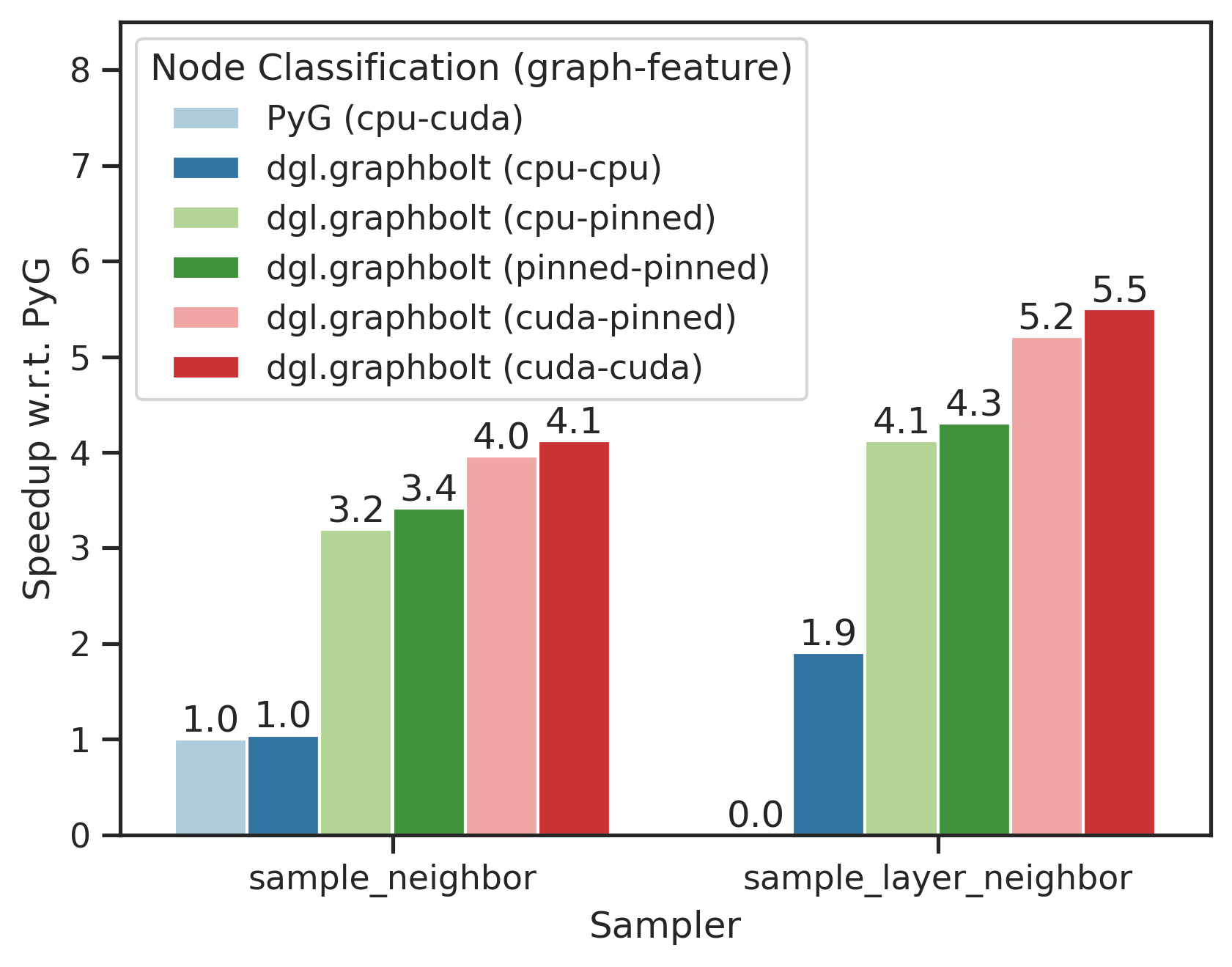
在提供经过极致优化的 Neighbor Sampler 实现的同时,我们还提供了一个新的即插即用替代方案,即来自 NeurIPS 2023 的 Layer Neighbor Sampler。可以看出,结合 GPU 加速、管道并行以及最先进的算法,我们相对于 PyG 提供了高达 5.5 倍的加速。有关 DGL 2.1 新功能的更多信息,请参阅我们的版本说明。
开始使用 DGL 2.1
您可以使用 pip 或 conda 在任何平台上轻松安装带有 dgl.graphbolt 的 DGL 2.1。深入学习我们更新后的 使用 GraphBolt 进行 GNN 随机训练教程,并在 Google Colab 中体验我们的 节点分类和链接预测示例。无需设置本地环境——只需点击即可!我们还更新了现有的 7 个全面的单 GPU 示例和 1 个多 GPU 示例,增加了 GPU 加速选项。DGL 2.1 将包含在预计于 2024 年 3 月底发布的 NVIDIA DGL container 24.03 版本中。
我们欢迎您的反馈,您可以通过 Github issues 和 Discuss posts 与我们联系。加入我们的 Slack 频道以获取最新动态并与社区交流。
06 三月
作者 Muhammed Fatih Balin,类别 发布