
DGL 2.0:精简您的 GNN 数据流水线,从瓶颈到提速
我们很高兴地宣布 DGL 2.0 发布,这是我们赋能开发者使用最前沿的图神经网络 (GNN) 工具的一个重要里程碑。传统上,数据加载一直是 GNN 训练的一个显著瓶颈。复杂的图结构和对高效采样的需求常常导致数据加载时间缓慢和资源限制。这会极大地阻碍您的 GNN 模型的训练速度和可扩展性。DGL 2.0 凭借革命性的数据加载框架 dgl.graphbolt 突破了这些限制,通过精简数据流水线,极大地提升了您的 GNN 训练速度。
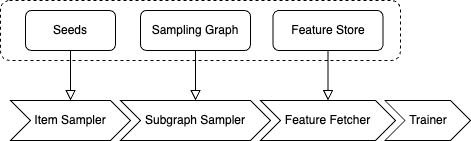
灵活的数据流水线 & 可定制的阶段
一种方案并非适用于所有情况——尤其是在处理各种图数据和 GNN 任务时。例如,链接预测需要负采样,而节点分类不需要;有些特征太大无法存储在内存中;偶尔,我们可能需要组合多个采样操作来形成子图。为了提供适应性强的算子同时保持高性能,dgl.graphbolt 与 PyTorch datapipe 无缝集成,依赖统一的“MiniBatch”数据结构来连接处理阶段。核心阶段定义如下:
- 项目采样 (Item Sampling):从整个训练集中随机选择一个子集(节点、边、图)作为下游计算的初始 Mini-batch。
- 负采样 (Negative Sampling)(用于链接预测):生成不存在的边作为负例。
- 子图采样 (Subgraph Sampling):根据输入节点/边生成子图。
- 特征获取 (Feature Fetching):为给定的输入从数据集中获取相关的节点/边特征。
- 数据移动 (Data Moving)(用于 GPU 训练):将数据移动到指定的设备进行训练。
# Seed edge sampler.
dp = gb.ItemSampler(train_edge_set, batch_size=1024, shuffle=True)
# Negative sampling.
dp = dp.sample_uniform_negative(graph, negative_ratio=10)
# Neighbor sampling.
dp = dp.sample_neighbor(graph, fanouts=[15, 10, 5])
# Fetch features.
dp = dp.fetch_feature(features, node_feature_keys=["feat"])
# Copy to GPU for training.
dp = dp.copy_to(device="cuda:0")
dgl.graphbolt 允许您插入自己的自定义处理步骤,为您的需求构建完美的数据流水线,例如:
# Seed edge sampler.
dp = gb.ItemSampler(train_edge_set, batch_size=1024, shuffle=True)
# Negative sampling.
dp = dp.sample_uniform_negative(graph, negative_ratio=10)
# Neighbor sampling.
dp = dp.sample_neighbor(graph, fanouts=[15, 10, 5])
# Exclude seed edges.
dp = dp.transform(gb.exclude_seed_edges)
# Fetch features.
dp = dp.fetch_feature(features, node_feature_keys=["feat"])
# Copy to GPU for training.
dp = dp.copy_to(device="cuda:0")
dgl.graphbolt 使您能够定制数据流水线中的阶段。使用预定义的 API 实现自定义阶段,例如从外部存储加载特征或添加自定义缓存机制(例如 GPUCachedFeature),并无缝集成这些自定义阶段,无需修改您的核心训练代码。
速度提升 & 内存效率
dgl.graphbolt 不仅为您提供灵活性,还在底层提供了顶级的性能。它具有紧凑的图数据结构,用于高效采样;闪电般快速的多线程邻居采样算子和边排除算子;以及一个内置选项,可以将大型特征张量存储在 CPU 主存之外。此外,dgl.graphbolt 负责协调所有硬件上的调度,最大限度地减少等待时间并提高效率。
dgl.graphbolt 为您的 GNN 训练带来了显著的速度提升,在我们的基准测试中,节点分类速度提高了 30% 以上,而在包含边排除的链接预测基准测试中,速度惊人地提高了约 390%。
| 每个 Epoch 的时间 (秒) | GraphSAGE | R-GCN |
|---|---|---|
| DGL Dataloader | 22.5 | 73.6 |
| dgl.graphbolt | 17.2 | 64.6 |
| 加速比 | 1.31x | 1.14x |
| 每个 Epoch 的时间 (秒) | 包含种子 | 排除种子 |
|---|---|---|
| DGL Dataloader | 37.75 | 135.32 |
| dgl.graphbolt | 15.51 | 27.62 |
| 加速比 | 2.43x | 4.90x |
对于像 OGBN-MAG240m 这样巨大的图在内存受限下的训练,dgl.graphbolt 也证明了其价值。尽管两者都利用了基于 mmap 的优化,但与 DGL dataloader 相比,dgl.graphbolt 提供了显著的加速。dgl.graphbolt 定义良好的组件 API 为贡献者未来优化非核心 RAM 解决方案简化了流程,确保即使是最大的图也能轻松应对。
| 不同内存大小下的迭代时间 (秒) | 128GB RAM | 256GB RAM | 384GB RAM |
|---|---|---|---|
| 朴素的 DGL dataloader | 内存溢出 (OOM) | 内存溢出 (OOM) | 内存溢出 (OOM) |
| 优化的 DGL dataloader | 65.42 | 3.86 | 0.30 |
| dgl.graphbolt | 60.99 | 3.21 | 0.23 |
更多内容
此外,DGL 2.0 包含了各种新增功能,例如异构关系 GCN 示例和几个数据集。系统、示例和文档都进行了改进,包括更新 CPU Docker 的 tcmalloc,支持稀疏矩阵切片算子以及增强各种示例。本次版本还发布了一系列用于构建图 Transformer 模型的实用工具,包括作为构建块的 NN 模块,例如位置编码器和层,以及演示其用法的示例和教程。此外,还修复了大量错误,解决了诸如 cuda12 的 cusparseCreateCsr 格式问题、DGL 节点/边特征相关的惰性设备复制问题等。有关 DGL 2.0 中新增功能和更改的更多信息,请参阅我们的发布说明。
开始使用 DGL 2.0
您可以使用 pip 或 conda 轻松地在任何平台上安装 DGL 2.0 和 dgl.graphbolt。要立即上手,请深入了解我们全新的使用 GraphBolt 进行 GNN 随机训练教程,并在 Google Colab 中尝试我们的节点分类和链接预测示例。无需设置本地环境——只需点击即可!DGL 2.0 的第一个版本与 dgl.graphbolt 一起发布,功能强大,包含 7 个全面的单 GPU 示例和 1 个多 GPU 示例,涵盖了广泛的任务。
我们欢迎您的反馈,您可以通过 Github issues 和 Discuss posts 与我们联系。加入我们的 Slack 频道,了解最新动态并与社区交流。
1月26日