
DGL 1.0:赋能人人可用的图机器学习
我们激动地宣布 DGL 1.0 来了,这是一个用于图深度学习的尖端机器学习框架。在过去三年里,学术界和工业界对这项技术的兴趣日益增长。我们的框架收到了来自各种场景的需求,从最先进模型的学术研究到将图神经网络(GNN)解决方案扩展到大型现实世界问题的工业需求。借助 DGL 1.0,我们旨在为所有用户提供全面且用户友好的解决方案,让他们能够充分利用图机器学习的优势。
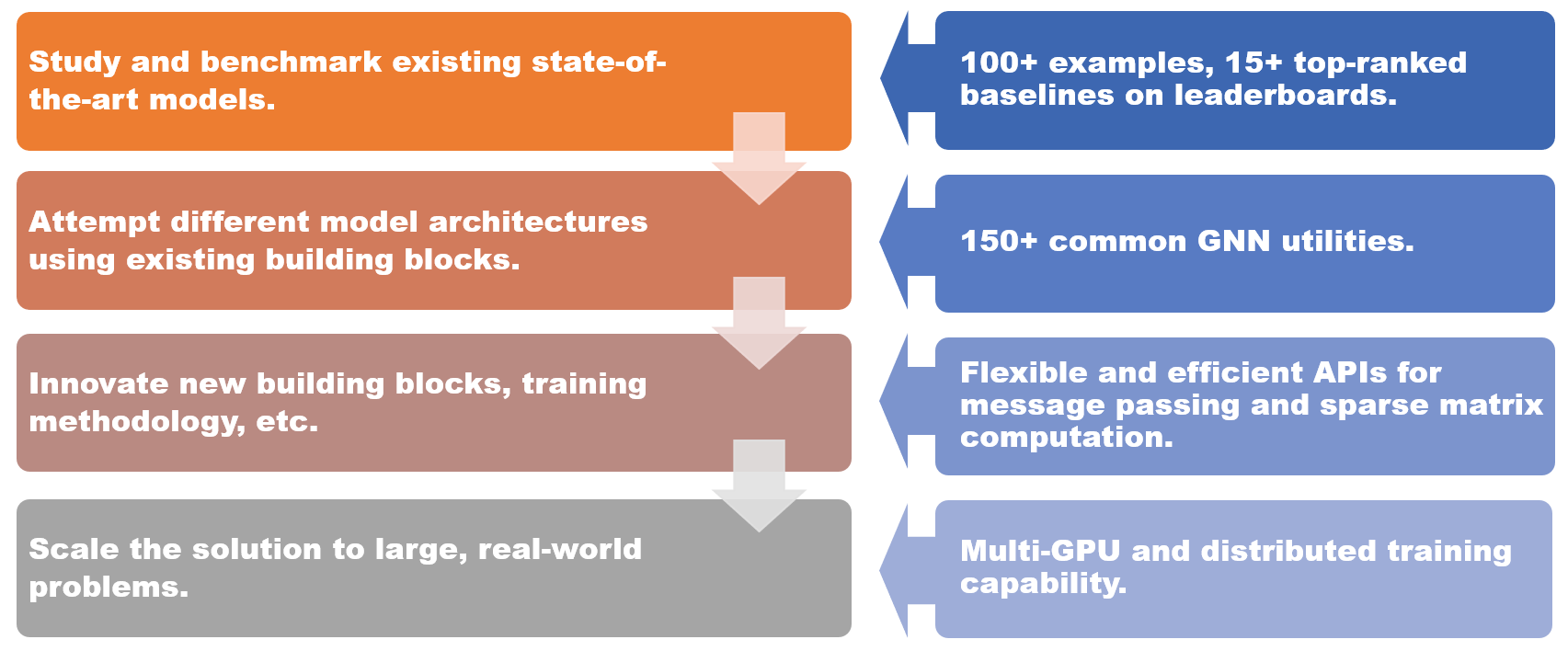
DGL 1.0 采用分层和模块化设计来满足各种用户需求。DGL 1.0 的主要特性包括
- 100+ 个最先进 GNN 模型的示例,Open Graph Benchmark (OGB) 上15+ 个顶级基线,可用于学习和集成
- 150+ 个 GNN 工具,包括 GNN 层、数据集、图数据转换模块、图采样器等,用于构建新的模型架构或基于 GNN 的解决方案
- 灵活高效的消息传递和稀疏矩阵抽象,用于开发新的 GNN 构建块
- 多 GPU 和分布式训练能力,可扩展到包含数十亿节点和边的图
DGL 1.0 中的新增和更新如图所示。本次发布的一个亮点是引入了 DGL-Sparse,这是一个新的专用软件包,用于处理以稀疏矩阵表示法定义的图机器学习模型。DGL-Sparse 不仅简化了图形卷积网络等成熟 GNN 的编程过程,还简化了扩散模型 GNN、超图神经网络和图 Transformer 等最新模型的编程过程。在下文中,我们将概述表示 GNN 的两种流行范式,即消息传递视角和矩阵视角,这促使了 DGL-Sparse 的创建。然后,我们将向您展示如何开始使用这个令人兴奋的新功能。
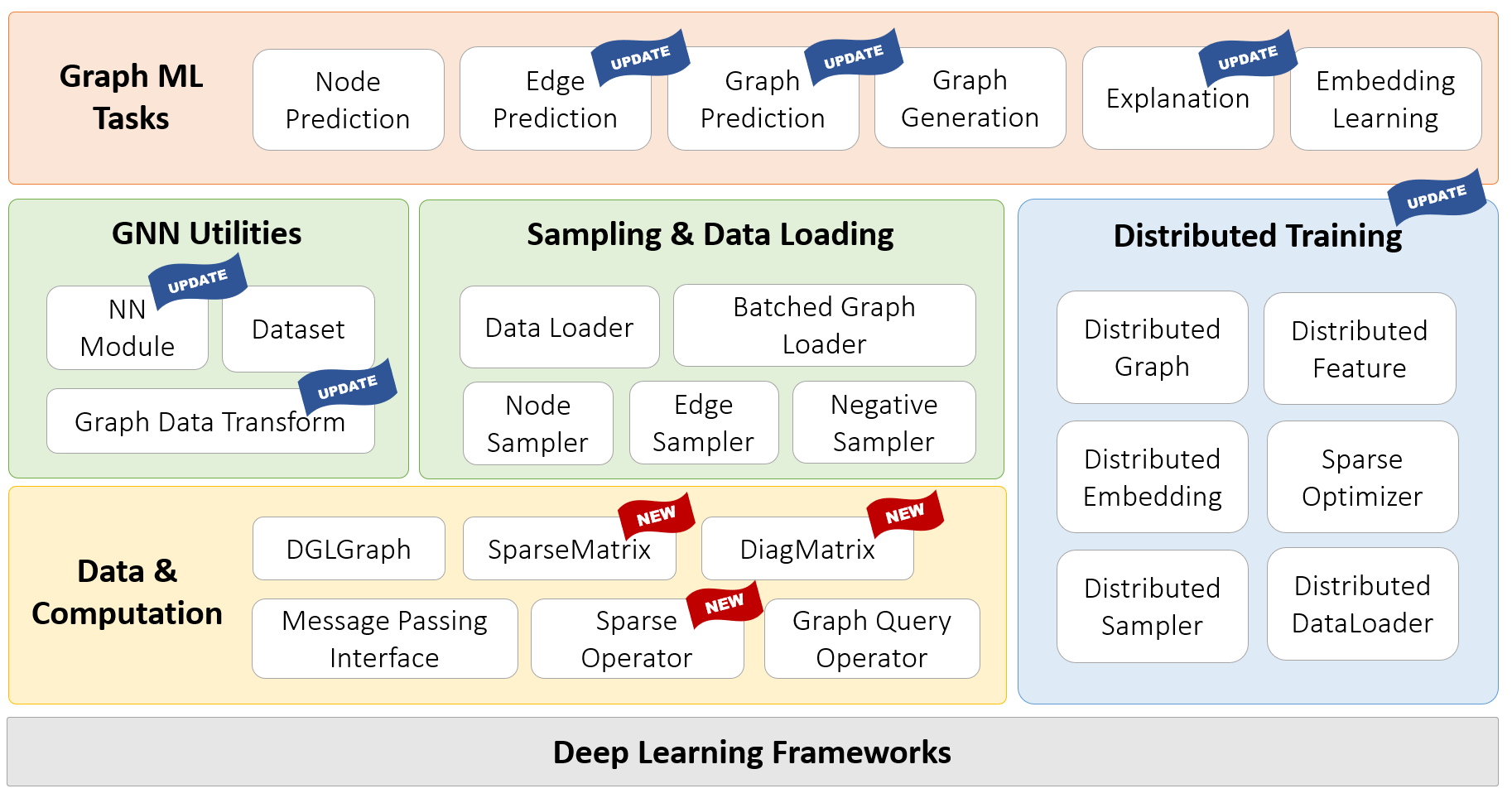
消息传递视角 vs. 矩阵视角
"你所讲的语言决定了你的思维方式,并影响你如何看待一切。"——选自电影《降临》中的 Louise Banks
表示图神经网络可以采用两种截然不同的形式。第一种,称为消息传递视角,从一种细粒度的局部视角来看待 GNN 模型,详细描述了消息如何沿边交换以及节点状态如何相应更新。或者,由于图与稀疏邻接矩阵在代数上等价,许多研究人员选择从一种粗粒度的全局视角来表达他们的 GNN 模型,强调涉及稀疏邻接矩阵和密集特征张量的操作。
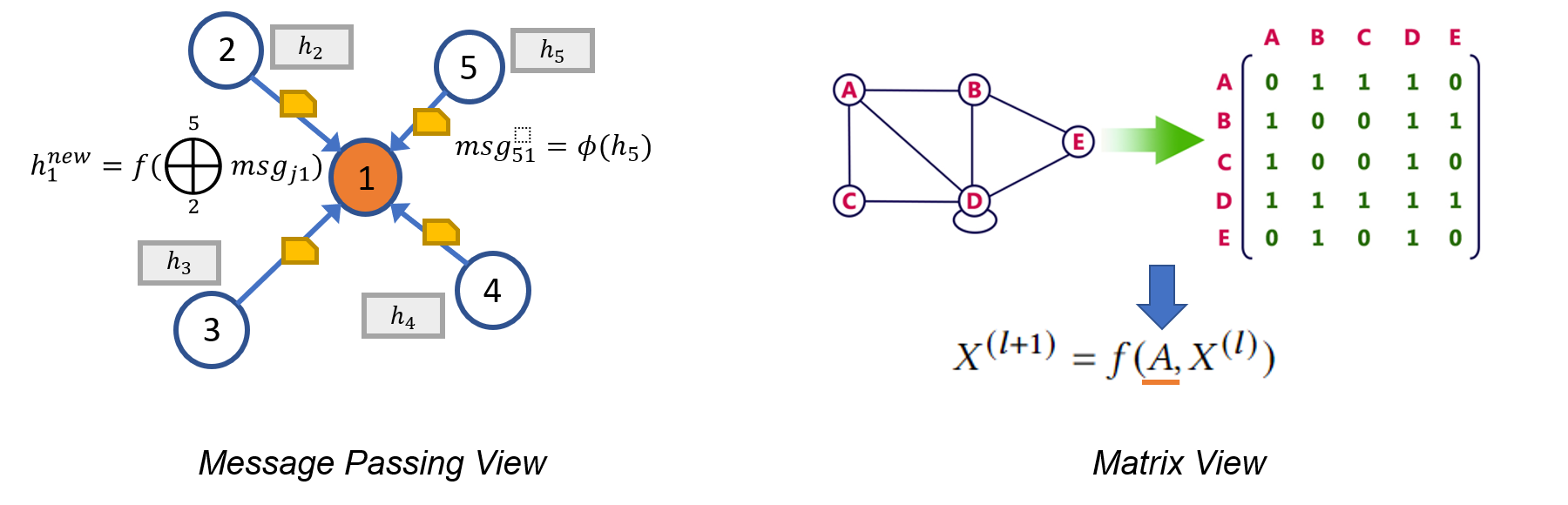
这些局部和全局视角有时可以互换,但更多时候,它们提供了对 GNN 基本原理和局限性的补充性见解。例如,消息传递视角突出了 GNN 与 Weisfeiler Lehman (WL) 图同构测试之间的联系,后者也依赖于聚合来自邻居的信息(如 Xu 等人,2018 年 中所述)。同时,矩阵视角对 GNN 的代数属性提供了有价值的理解,从而产生了诸如过度平滑现象(如 Li 等人,2018 年 中讨论)等有趣的发现。总之,消息传递视角和矩阵视角都是研究和描述 GNN 不可或缺的工具,这正是我们在 DGL 1.0 中将展示的关键功能的动机所在。
DGL Sparse:图机器学习的稀疏矩阵抽象
在 DGL 1.0 中,我们很高兴地宣布发布 DGL Sparse,这是在 DGL 现有消息传递接口之外的一个新子包(dgl.sparse),以实现对 GNN 模型全谱的支持。DGL Sparse 提供了专门用于图机器学习的稀疏矩阵类和操作,使得用矩阵视角描述 GNN 的编程变得更容易。在下一节中,我们将展示几个 GNN 示例,展示它们的数学公式以及在 DGL Sparse 中的相应代码实现。
图卷积网络 (Kipf 等人,2017 年) 是 GNN 建模的开创性工作之一。GCN 可以用消息传递视角和矩阵视角来表达。下面的代码比较了 DGL 中这两种不同的视角和实现方式。

import dgl.function as fn # DGL message passing functions
class GCNLayer(nn.Module):
...
def forward(self, g, X):
g.ndata['X'] = X
g.ndata['deg'] = g.in_degrees().float()
g.update_all(self.message, fn.sum('m', 'X_neigh'))
X_neigh = g.ndata['X_neigh']
return F.relu(self.W(X_neigh))
def message(self, edges):
c_ij = (edges.src['deg'] * edges.dst['deg']) ** -0.5
return {'m' : edges.src['X'] * c_ij}
import dgl.sparse as dglsp # DGL 1.0 sparse matrix package
class GCNLayer(nn.Module):
...
def forward(self, A, X):
D_invsqrt = dglsp.diag(A.sum(1)) ** -0.5
A_norm = D_invsqrt @ A @ D_invsqrt
return F.relu(self.W(A_norm @ X))
基于图扩散的 GNN。图扩散是将节点特征/信号沿着边传播或平滑的过程。许多经典的图算法(例如 PageRank)属于这一类别。一系列研究表明,将图扩散与神经网络结合是提高模型预测效果的一种有效且高效的方法。下面的公式描述了一个代表性模型的核心计算——近似个性化神经预测传播 (Gasteiger 等人,2018 年),该模型可以在 DGL Sparse 中直接实现。
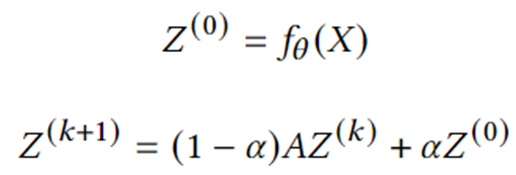
class APPNP(nn.Module):
...
def forward(self, A, X):
Z_0 = Z = self.f_theta(X)
for _ in range(self.num_hops):
A_drop = dglsp.val_like(A, self.A_dropout(A.val))
Z = (1 - self.alpha) * A_drop @ Z + self.alpha * Z_0
return Z
超图神经网络。超图是图的推广,其中一条边可以连接任意数量的节点(称为超边)。超图在需要捕获高阶关系的场景中特别有用,例如电子商务平台中的共同购买行为,或引文网络中的共同作者关系等。超图通常由其稀疏关联矩阵表征,因此超图神经网络(HGNN)通常以稀疏矩阵表示法定义。Feng 等人,2018 年 提出的超图卷积的公式和代码实现如下所示。
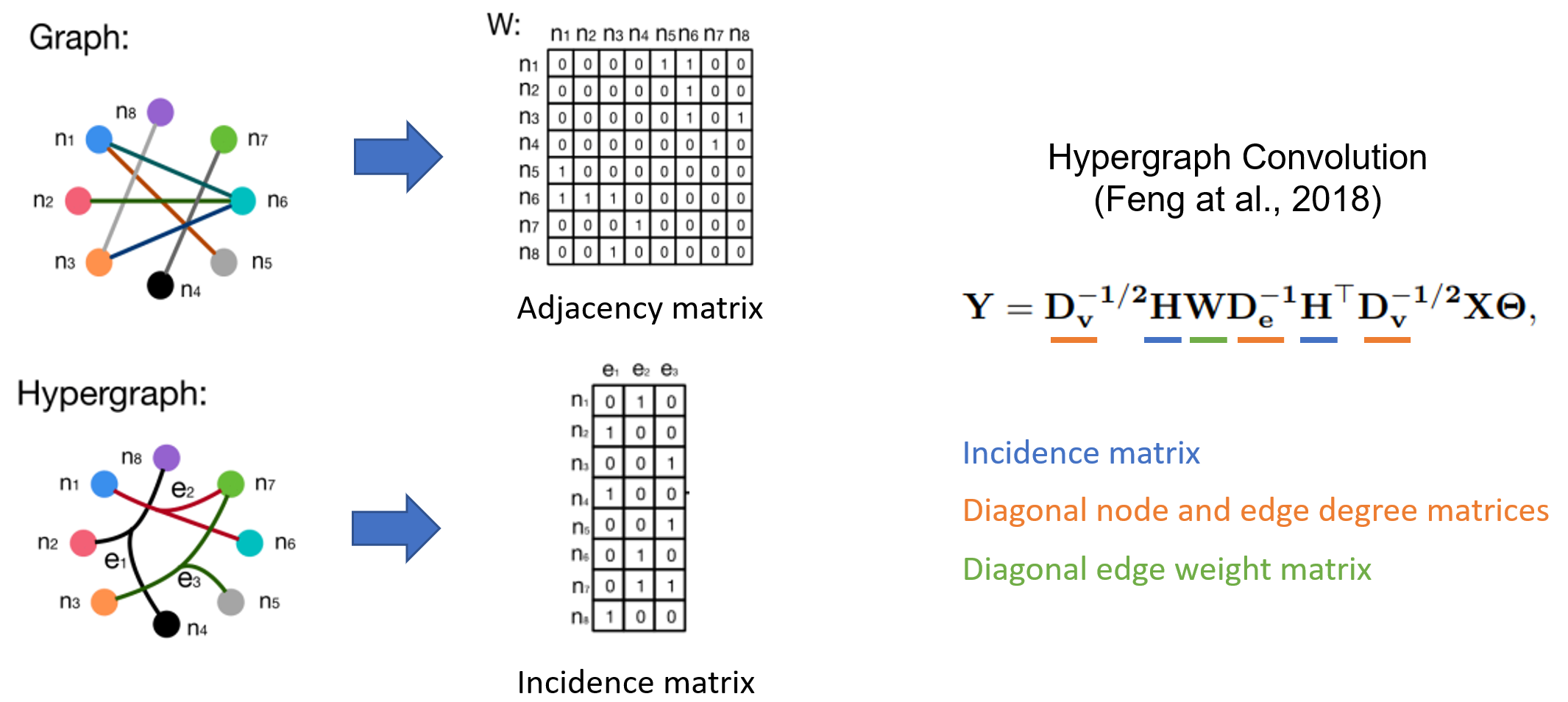
class HypergraphConv(nn.Module):
...
def forward(self, H, X):
d_V = H.sum(1) # node degree
d_E = H.sum(0) # edge degree
n_edges = d_E.shape[0]
D_V_invsqrt = dglsp.diag(d_V**-0.5) # D_V ** (-1/2)
D_E_inv = dglsp.diag(d_E**-1) # D_E ** (-1)
W = dglsp.identity((n_edges, n_edges))
L = D_V_invsqrt @ H @ W @ D_E_inv @ H.T @ D_V_invsqrt
return self.Theta(L @ X)
图 Transformer。Transformer 已被证明是自然语言处理和计算机视觉中有效的学习架构。研究人员也开始将 Transformer 的使用扩展到图学习。(Dwivedi 等人,2020 年) 的一项开创性工作提出将全对多头注意力限制在图中的连接节点对上。借助 DGL Sparse,实现这种新公式现在是一个简单的过程,只需大约 10 行代码。
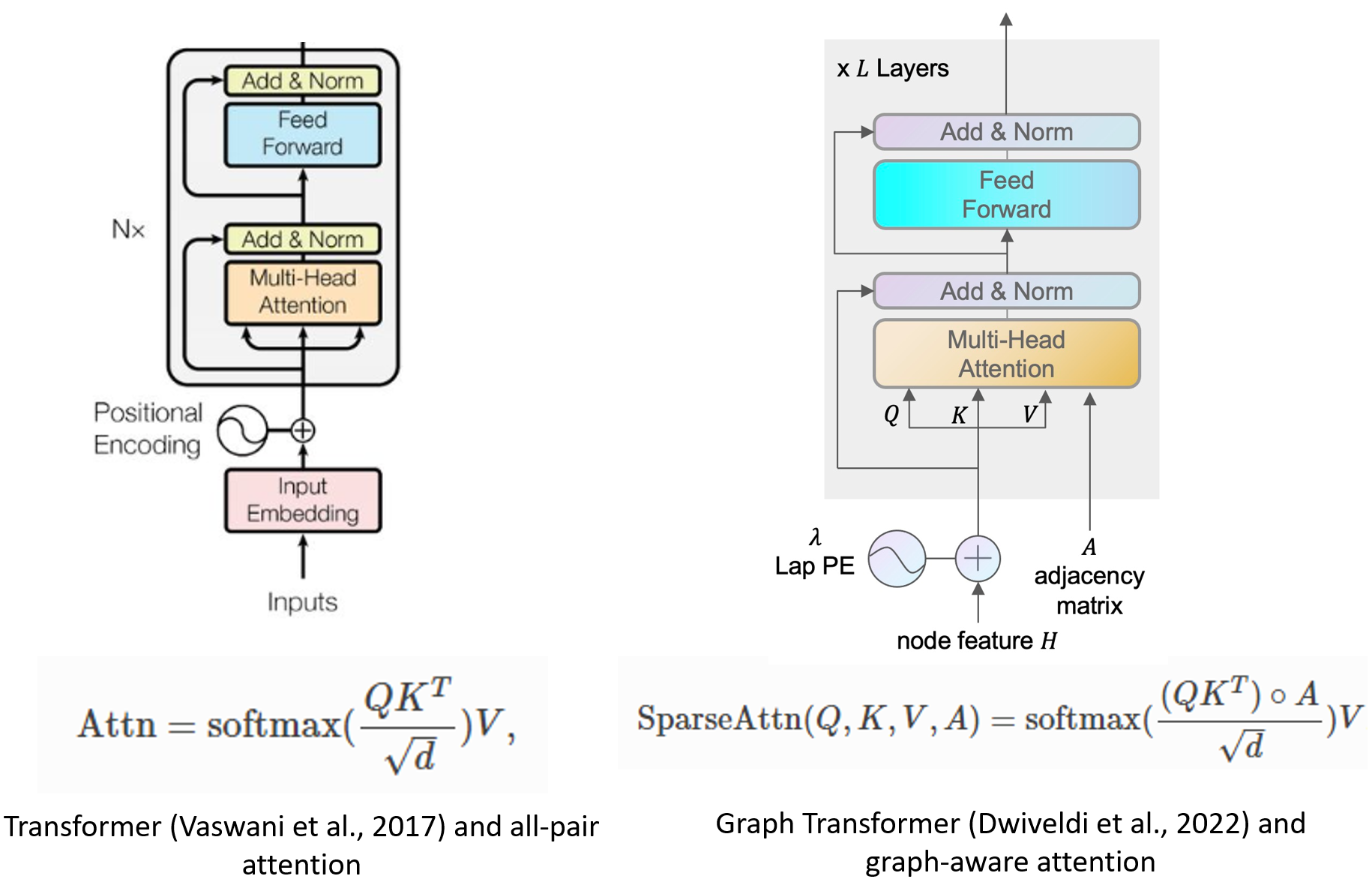
class GraphMHA(nn.Module):
...
def forward(self, A, h):
N = len(h)
q = self.q_proj(h).reshape(N, self.head_dim, self.num_heads)
q *= self.scaling
k = self.k_proj(h).reshape(N, self.head_dim, self.num_heads)
v = self.v_proj(h).reshape(N, self.head_dim, self.num_heads)
attn = dglsp.bsddmm(A, q, k.transpose(1, 0)) # [N, N, nh]
attn = attn.softmax()
out = dglsp.bspmm(attn, v)
return self.out_proj(out.reshape(N, -1))
DGL Sparse 的关键特性
为了高效地处理不同的用例,DGL Sparse 设计了两个关键特性,使其区别于其他稀疏矩阵库,例如 scipy.sparse 或 torch.sparse
- 自动稀疏格式选择。DGL Sparse 消除了选择正确的稀疏矩阵存储数据结构(也称为稀疏格式)的复杂性。用户只需调用
dgl.sparse.spmatrix即可创建一个稀疏矩阵,DGL 的内部稀疏矩阵将根据预期的操作自动选择最优格式。 - 标量或向量非零元素。GNN 模型通常将边与多通道权重向量关联起来,例如图 Transformer 示例中演示的多头注意力向量。为了适应这一点,DGL Sparse 允许非零元素具有向量形状,并将常见的稀疏操作(例如稀疏-密集矩阵乘法 (SpMM))扩展到处理这种新形式(如在图 Transformer 示例中的
bspmm操作所示)。
通过利用这些设计特性,与之前使用消息传递接口实现矩阵视角模型相比,DGL Sparse 平均减少了 2.7 倍的代码长度。简化的代码还使框架开销减少了 43%。此外,DGL Sparse 与 PyTorch 兼容,可以轻松地与 PyTorch 生态系统中提供的各种工具和软件包集成。
DGL 1.0 入门
该框架已在所有平台上可用,可以使用 pip 或 conda 轻松安装。要开始使用 DGL Sparse,请查看新的快速入门教程,并在 Google Colab 中试用,无需设置本地环境。除了您在上面看到的示例外,DGL Sparse 的首次发布还包括 5 个教程和 11 个端到端示例,以帮助您学习和理解此新软件包的不同用法。
我们欢迎您的反馈,您可以通过 Github issues 和 Discuss posts 联系我们。加入我们的 Slack 频道,及时获取最新信息并与社区联系。
有关 DGL 1.0 中新增功能和更改的更多信息,请参阅我们的发布说明。
(横幅图片由 Midjourney 生成。)
20二月