
v0.8 发布亮点
我们很高兴地宣布 DGL v0.8 的发布,该版本带来了许多新功能以及系统性能的提升。亮点如下:
- 迷你批量采样管线的重大更新,更高的可定制性,更多的优化;对于 OGBN-Products 上的监督式和非监督式 GraphSAGE,速度分别提升 3.9 倍和 1.5 倍,只需更改一行代码。
- 流行的异构图神经网络模块的显著加速和代码简化(RGCN 卷积最高提速 36 倍,HGT 卷积最高提速 12 倍)。新增 11 个现成的神经网络模块,用于构建链接预测、异构图学习和 GNN 解释模型。
- GNNLens:一个由 DGL 支持的工具,用于使用 GNN 解释模型可视化和理解图数据。
- 新增创建、转换和增强图数据集的功能,使得更容易进行图对比学习研究或将图数据用于不同任务。
- DGL-Go:一个新的 GNN 模型训练命令行工具,它提供简单的接口,用户可以快速将其 GNN 应用于其问题,并使用最先进的 GNN 模型进行实验编排。
迷你批量采样管线更新
在训练神经网络时,迷你批量采样被用来提升模型性能并使其能扩展到大型数据集。在图上的 GNN 环境中,迷你批量训练带来了新的复杂性,可以分解为以下四个主要步骤:
- 从原始图中提取子图。
- 对子图执行转换。
- 获取子图的节点/边特征。
- 将子图及其特征作为输入传递给你的 GNN 模型并更新参数。
其中,步骤 1-3 是 GNN 独有的,并且代价很高。在 v0.7 中,我们发布了在 GPU 上转换子图以加速步骤 2 的功能,但其他两个步骤可能仍然是瓶颈。在此版本中,我们进一步优化了整个管线,以达到更好的性能。接下来,我们将简要介绍其背后的技术方案。
为了加速子图提取,我们利用了 CUDA 统一虚拟寻址 (UVA)。
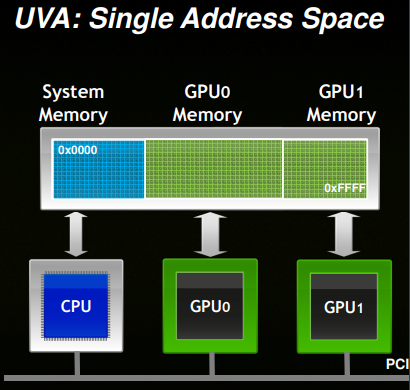
(图片来源:https://developer.download.nvidia.cn/CUDA/training/cuda_webinars_GPUDirect_uva.pdf)
CUDA UVA 允许用户创建超出 GPU 内存容量的内存数据,同时仍利用 GPU 内核进行快速计算。将整个图结构及其特征存储在 UVA 中,可以使用 GPU 内核高效地提取子图,这对于训练大规模 GNN 非常有效 [1][2]。在此版本中,用户可以通过在 DataLoader 中设置 use_uva 标志来开启 UVA 模式,如下例所示:
g = ... # some DGLGraph data
train_nids = ... # training node IDs
sampler = dgl.dataloading.MultiLayerNeighborSampler(
fanout=[10, 15])
dataloader = dgl.dataloading.DataLoader(
g, train_nids, sampler,
device='cuda:0', # perform sampling on GPU 0
batch_size=1024,
shuffle=True,
use_uva=True # turn on UVA optimization
)
为了加速特征获取(步骤 3),DGL 0.8 支持预取节点/边特征,以便模型计算可以与数据移动并行发生。用户可以在采样器对象中指定要预取的特征和标签。
g = ... # some DGLGraph data
train_nids = ... # training node IDs
sampler = dgl.dataloading.MultiLayerNeighborSampler(
fanout=[10, 15],
prefetch_node_feats=['feat'], # prefetch node feature 'feat'
prefetch_labels=['label'], # prefetch node label 'label'
)
dataloader = dgl.dataloading.DataLoader(
g, train_nids, sampler,
device='cuda:0', # perform sampling on GPU 0
batch_size=1024,
shuffle=True,
use_uva=True # turn on UVA optimization
)
这些优化为监督式和非监督式迷你批量训练带来了显著的加速。我们将其与原始的 CPU 采样但在 GPU 上训练的管线进行比较,用于在使用 A100 GPU 的 ogbn-papers100M 图上训练一个两层 GraphSAGE 模型。我们观察到在单 GPU 上,监督式和非监督式 GraphSAGE 的速度分别提高了 3.9 倍和 1.5 倍。此加速也适用于多 GPU 训练。
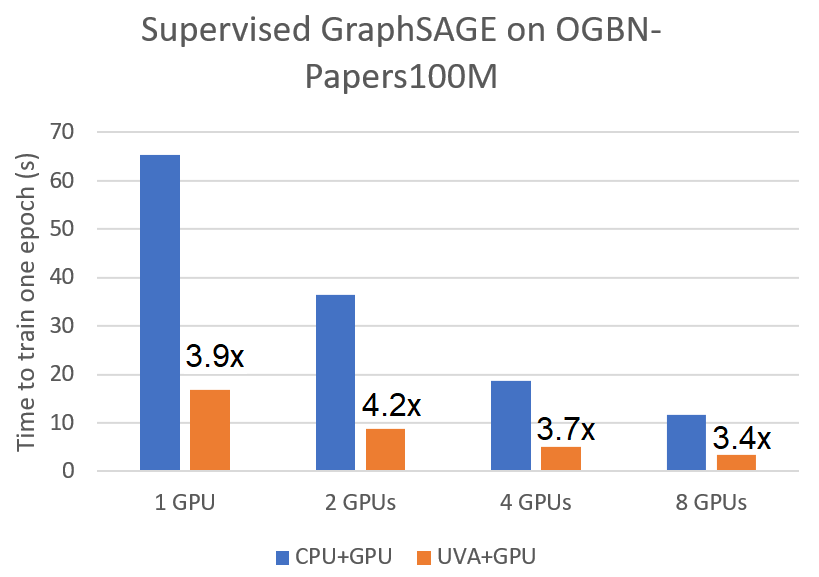 |
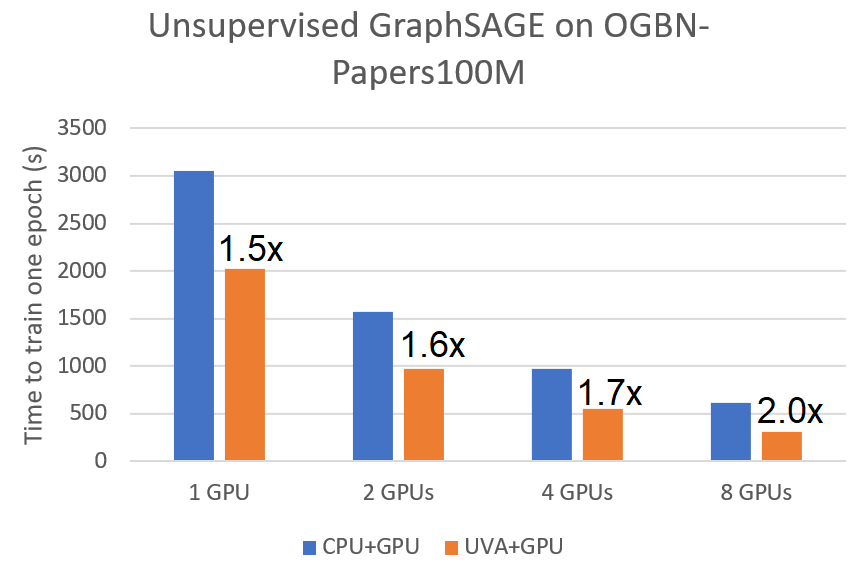 |
|---|---|
| 监督式 GraphSAGE 的提速 | 非监督式 GraphSAGE 的提速 |
在 DGL v0.8 中定义新的采样器也更容易,只需遵循一个简单的接口 sample 即可。用户可以选择指定如何为每个样本预取特征。例如,Cluster-GCN 使用的簇采样器只需几行代码即可实现。
class ClusterGCNSampler:
def __init__(self, g, k, prefetch_ndata=None):
part_ids = dgl.metis_partition_assignment(g, k)
# convert partition assignment to bins of nodes
part_sizes = torch.histogram(part_ids.float(), k)[0].int()
self.node_bins = torch.split(torch.argsort(part_ids), part_sizes)
# save the node feature names to be prefetched
self.prefetch_ndata = prefetch_ndata
def sample(self, g, part_ids):
"""Sample a subgraph given a list of partition IDs."""
node_ids = torch.cat([self.node_bins[pid] for pid in part_ids])
sg = g.subgraph(node_ids) # get an induced subgraph
# tell which feature to pre-fetch
dgl.set_node_lazy_feature(sg, self.prefetch_ndata)
return sg
v0.8 中的新采样器
dgl.dataloading.ClusterGCNSampler:来自 Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks 的采样器。dgl.dataloading.ShaDowKHopSampler:来自 Deep Graph Neural Networks with Shallow Subgraph Samplers 的采样器。
如果没有社区的帮助,这一显著的改进将不会实现。我们感谢来自 NVIDIA 的 Xin Yao (@yaox12) 和 Dominique LaSalle (@nv-dlasalle),以及来自 UIUC 的 David Min (@davidmin7) 的贡献。
延伸阅读
- 用户指南章节:定制图采样器。
- 用户指南章节:编写带特征预取的图采样器。
- ClusterGCN 的示例实现。
神经网络模块更新
异构 GNN 众所周知既难以实现,也难以优化。在此版本中,我们显著提高了 dgl.nn.RelGraphConv 和 dgl.nn.HGTConv 的速度——这是用于在异构图上训练的两个最先进的神经网络模块,有时与各种基准相比快了一个数量级 [3]。
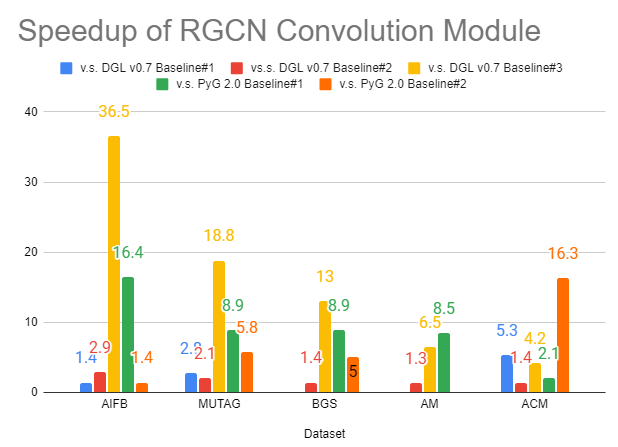 |
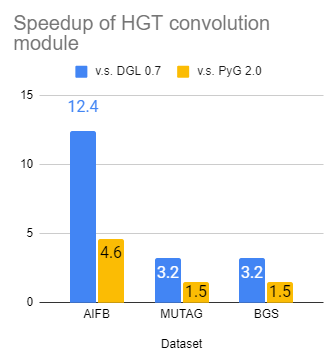 |
|---|---|
| RGCN 卷积的提速 | HGT 卷积的提速 |
更重要的是,编写高效的异构图卷积变得容易得多。以下是使用新的 nn.TypedLinear 模块在 0.8 中实现的 RGCN 卷积的最小示例:
class RGCNConv(nn.Module):
def __init__(self, in_size, out_size, num_etypes):
# TypedLinear is a new module in 0.8!
self.linear_r = dgl.nn.TypedLinear(in_size, out_size, num_etypes)
def forward(self, g, x, etype):
g.ndata['x'] = x
g.edata['etype'] = etype
g.update_all(self.message, dgl.function.sum('m', 'h'))
return g.ndata['h']
def message(self, edges):
return self.linear_r(edges.src['h'], edges.data['etype'])
此版本还带来了 11 个新的神经网络模块,涵盖了社区最常请求的功能。其中包括但不限于:
- 用于链接预测的常用边评分模块(例如 TransE、TransR 等)。
- 用于异构图的线性投影模块和嵌入模块(
nn.HeteroLinear和nn.HeteroEmbedding)。 GNNExplainer模块。
通过可视化和基于 GNN 的解释来理解图
使用基于 GNN 的解释模型理解图数据已成为重要的研究课题。我们与香港科技大学 VisLab 团队合作发布了 GNNLens,这是一个用于图神经网络的交互式可视化工具。
要安装 GNNLens,请运行 pip install gnnlens。
它提供了用于指定要可视化数据的 Python API。例如,以下代码展示了如何加载 DGL 内置的 Cora 图数据集并将其可视化:
from dgl.data import CoraGraphDataset
dataset = CoraGraphDataset()
G = dataset[0]
from gnnlens import Writer
# Specify the path to create a new directory for dumping data files.
writer = Writer('tutorial_graph')
writer.add_graph(name='Cora', graph=cora_graph)
writer.add_graph(name='Citeseer', graph=citeseer_graph)
# Finish dumping
writer.close()
运行脚本后,您可以使用以下命令启动 GNNLens:
gnnlens --logdir tutorial_graph
然后在浏览器中看到网页:

GNNLens 不仅能够可视化原始图数据,还设计用于检查图神经网络,例如运行解释模型来解释预测。请查看项目 README 中的教程:https://github.com/dmlc/gnnlens2。
可组合的图数据转换
图数据增强已成为图对比学习或一般结构预测的重要组成部分。新版本使得将各种图增强和转换算法组合并应用于所有 DGL 内置数据集变得更容易。新的 dgl.transforms 包遵循 PyTorch Dataset Transforms 的风格。用户可以通过所有 DGL 数据集的 transform 关键字参数指定要使用的转换:
import dgl
import dgl.transforms as T
t = T.Compose([
T.AddSelfLoop(),
T.GCNNorm(),
])
dataset = dgl.data.CoraGraphDataset(transform=t)
g = dataset[0] # graph and features will be transformed automatically
DGL v0.8 提供了 16 个常用的数据转换 API。有关更多信息,请参阅API 文档。
让图数据集易于用于各种研究非常重要。一个常见的场景是将数据集调整用于其最初设计以外的任务(例如,在最初用于节点分类的 Cora 上训练链接预测模型)。因此,我们为此目的添加了两个数据集适配器(dgl.data.AsNodePredDataset 和 dgl.data.AsLinkPredDataset)。我们还支持生成新的训练/验证/测试集划分并保存以备后用:
import dgl
dataset = dgl.data.CoraGraphDataset()
# make a Cora dataset suitable for link prediction
# add train/val/test split and negative samples
dataset = dgl.data.AsLinkPredDataset(dataset, split_ratio=[0.8, 0.1, 0.1], neg_ratio=3)
还有一件事
由于 GNN 仍然是一个新兴且蓬勃发展的领域,我们收到了许多用户提出的“如何开始”的问题:
- “我听说过 GNN,如何在自己的数据集上开始训练 GNN 模型?”
- “我想了解更多 GNN 知识,如何开始使用 SOTA 基线进行实验?”
- “我有一些新的研究想法,如何在现有 GNN 模型的基础上进行构建?”
为了让这些第一步更容易,我们开发了 DGL-Go,一个命令行工具,用户可以快速获取最新的 GNN 研究进展。
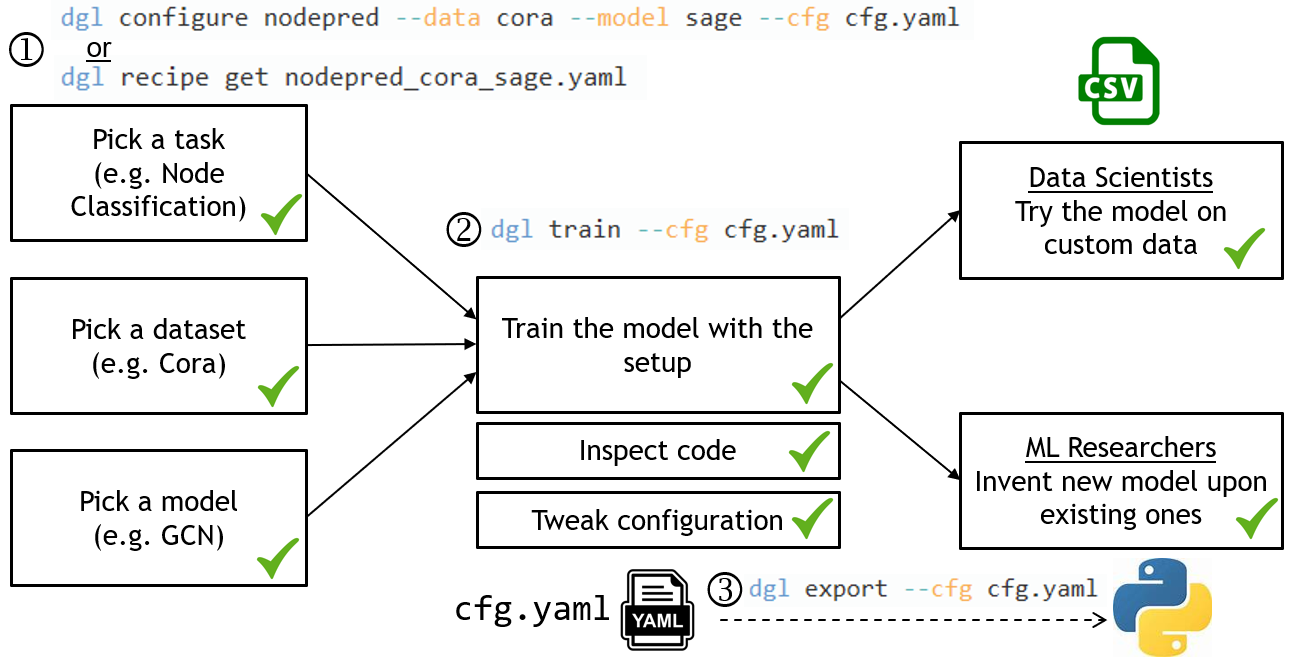
使用 DGL-Go 非常简单,只需三步:
- 使用
dgl configure选择你感兴趣的任务、数据集和模型。它会生成一个配置文件,以便后续使用。你也可以使用dgl recipe get获取我们提供的配置文件。 - 使用
dgl train根据配置启动训练并查看结果。 - 使用
dgl export生成一个自包含、可复现的 Python 脚本,用于高级自定义,或在以 CSV 格式存储的自定义数据上尝试模型。
只需通过 pip install dglgo 安装 DGL-Go,并查看项目 README 获取更多详细信息。
延伸阅读
DGL v0.8 的完整发布说明。
参考文献
[1] PyTorch-Direct: Enabling GPU Centric Data Access for Very Large Graph Neural Network Training with Irregular Accesses
[2] TorchQuiver: https://github.com/quiver-team/torch-quiver
[3] 我们将新的 nn.RelGraphConv 模块与 DGL 和 PyG 中的多个现有基线进行了比较。对于 DGL v0.7,基线#1 使用旧的 nn.RelGraphConv 模块并设置 low_mem=False;基线#2 使用旧的 nn.RelGraphConv 并设置 low_mem=True;基线#3 使用 nn.HeteroGarphConv。对于 PyG,基线#1 使用 nn.RGCNConv,而基线#2 使用 nn.FastRGCNConv。所有基准测试都在一块 NVIDIA T4 GPU 卡上进行。
01 三月