
v0.7 发布亮点
v0.7 在底层系统基础设施和高层面向用户的工具方面都带来了改进。其中许多包含来自用户社区的贡献。我们很高兴看到这一增长趋势,并欢迎未来更多的贡献。以下是值得注意的更新。
基于 GPU 的邻居采样
我们与 NVIDIA 合作,使 DGL 支持在 GPU 上进行均匀邻居采样和 MFG 转换。这消除了每次迭代中将样本从 CPU 移动到 GPU 的需要,同时利用 GPU 加速加快了采样步骤。因此,在 g3.16x 实例上对 ogbn-product 图上的 GraphSAGE 进行实验,获得了 >10 倍的速度提升(从每 epoch 113 秒减少到 11 秒)。要启用此功能,请使用 GPU 图创建 NodeDataLoader,并将采样设备指定为 GPU。
g = ... # create a graph
g = g.to('cuda:0') # move the graph to GPU
# create a data loader
dataloader = dgl.dataloading.NodeDataLoader(
g, # now accepts graph on GPU
train_nid,
sampler,
device=torch.device('cuda:0'), # specify the sampling device
num_workers=0, # num_workers must be 0
batch_size=1000,
drop_last=False,
shuffle=True)
# training loop
for input_nodes, output_nodes, sample_graphs in dataloader:
# the produced sample_graphs are already on GPU
train_on(input_nodes, output_nodes, sample_graphs)
相应的文档已更新。
- 新增用户指南章节 使用 GPU 进行邻域采样,介绍何时以及如何使用此新功能。
- NodeDataLoader 的 API 文档。
我们感谢来自 NVIDIA 的 @nv-dlasalle 贡献了用于执行邻居采样和 MFG 转换的 CUDA 内核。
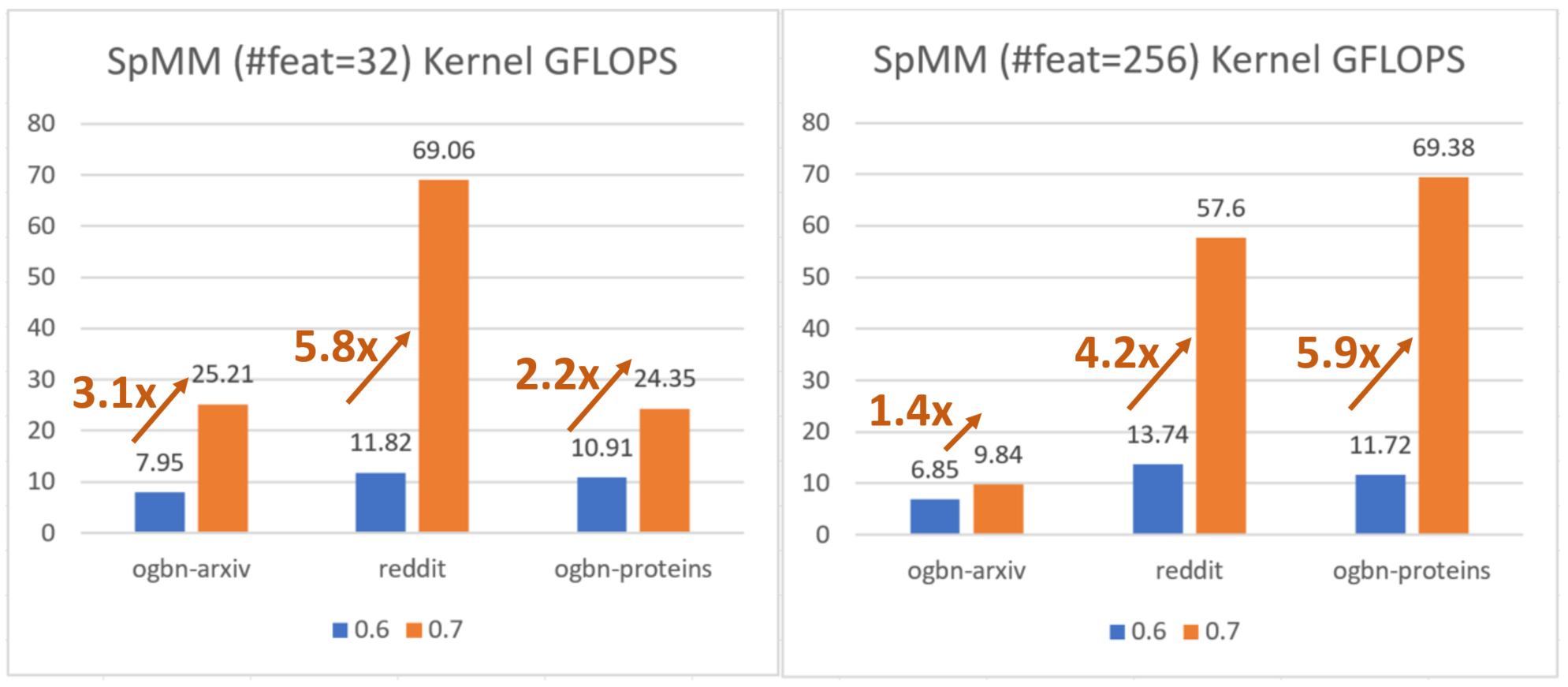
改进的 CPU 消息传递内核
用于 CPU 上 GNN 消息传递的核心 SpMM 内核已重新实现。新内核对 CSR 矩阵进行分块(tiling),并利用 Intel 的 LibXSMM 进行内核生成。请阅读论文 https://arxiv.org/abs/2104.06700 获取更多详情。对于 Xeon CPU,该功能会自动开启,并显示出显著的速度提升。我们感谢 @sanchit-misra 和 Intel 贡献了新的 CPU 内核。
更好的 NodeEmbedding,用于多 GPU 训练和分布式训练
DGL 现在利用 NCCL 在训练期间同步稀疏节点嵌入 (dgl.nn.NodeEmbedding) 的梯度。当用户为 torch.distributed.init_process_group 指定 nccl 作为后端时,它会自动启用。我们的实验表明,在 g4dn.12xlarge (4 T4 GPU) 实例上对 ogbn-mag 图上的 RGCN 进行训练,获得了 20% 的速度提升(从每 epoch 47.2 秒减少到 39.5 秒)。我们感谢来自 @nv-dlasalle 和 NVIDIA 的努力。 分布式节点嵌入现在使用同步梯度更新,使训练更稳定。
DGL Kubernetes Operator
奇虎 360 构建了一个 DGL Operator,可以在 Kubernetes 上运行图神经网络的分布式或非分布式训练。请查看他们的仓库了解用法:https://github.com/Qihoo360/dgl-operator。
其他性能提升
除了主要的特性改进之外,我们还收到了社区贡献者在修复性能问题方面的帮助。值得注意的是,DGL 的 CPU 随机游走采样在中大型图上提升了 24 倍;在十亿级别规模的图上,分布式训练集分割的内存消耗下降了约 7 倍。
更多模型
和往常一样,本次发布为仓库带来了批量新增的 19 个模型示例,使总数达到 90 多个。为了帮助用户找到符合他们需求的示例(例如特定主题、数据集),我们在 dgl.ai 上推出了一个新的搜索工具,支持按关键词查找示例。

以下是 v0.7 中新增的模型。
- 用于学习对象、关系和物理的交互网络
- 用于 OGB-LSC 节点分类的多 GPU RGAT
- 带有完全不平衡标签的网络嵌入
- 改进的时序图网络
- 扩散卷积循环神经网络
- 用于处理大型和时空图的门控注意力网络
- DeeperGCN
- 深度图对比表示学习
- 受经典迭代算法启发的图神经网络
- GraphSAINT
- 标签传播
- 结合标签传播和简单模型优于图神经网络
- GCNII
- 在 GPU 上的潜在狄利克雷分配
- 一种基于异构信息网络的跨领域保险推荐系统,用于冷启动用户
- 五种异构图模型:HetGNN/GTN/HAN/NSHE/MAGNN。因此也新增了带自动梯度的稀疏矩阵乘法和加法。
- 带小批量采样的异构图注意力网络
- 学习层次图神经网络用于图像聚类
多 GPU 和分布式训练教程
随着将 GNN 应用于大规模图的兴趣日益增长,我们收到许多用户关于如何利用多 GPU 或多机器进行加速的提问。在本次发布中,我们分别发布了两个关于节点分类和图分类的多 GPU 训练新教程。还有一个关于跨多机器分布式训练的新教程。所有教程均可在 docs.dgl.ai 获取。
更多阅读
26 七月