注意
跳转到末尾以下载完整的示例代码。
单机多 GPU Minibatch 图分类
在本教程中,您将学习如何使用多个 GPU 来训练用于图分类的图神经网络 (GNN)。本教程假定您已了解如何使用 GNN 进行图分类,否则我们建议您查看使用 GNN 进行图分类训练。
(时间估计:8 分钟)
要在单个 GPU 上训练 GNN,我们需要将模型、图以及其他张量(例如标签)放在同一个 GPU 上
import torch
# Use the first GPU
device = torch.device("cuda:0")
model = model.to(device)
graph = graph.to(device)
labels = labels.to(device)
图中(如果存在)的节点和边特征也将位于 GPU 上。之后,前向计算、后向计算和参数更新将在 GPU 上进行。对于图分类,每个 minibatch 梯度下降都会重复此过程。
使用多个 GPU 可以在单位时间内执行更多计算。这就像一个团队协同工作,每个 GPU 都是团队成员。我们需要将计算工作负载分布到各个 GPU 上,并让他们定期同步工作。PyTorch 为使用多个进程(每个 GPU 一个进程)执行此任务提供了便捷的 API,我们可以结合 DGL 使用它们。
直观地说,我们可以沿着数据维度分配工作负载。这使得多个 GPU 可以并行执行多个梯度下降的前向和后向计算。要将数据集分布到多个 GPU 上,我们需要将其分成多个大小相似的互斥子集,每个 GPU 一个子集。我们需要每个 epoch 重复随机划分以保证随机性。我们可以使用 GraphDataLoader(),它封装了一些 PyTorch API,并在数据加载中完成了图分类的任务。
一旦所有 GPU 完成其 minibatch 的后向计算,我们就需要在它们之间同步模型参数更新。具体来说,这包括收集所有 GPU 的梯度,对其进行平均,并在每个 GPU 上更新模型参数。我们可以使用 DistributedDataParallel() 包装 PyTorch 模型,这样模型参数更新将在内部首先调用梯度同步。
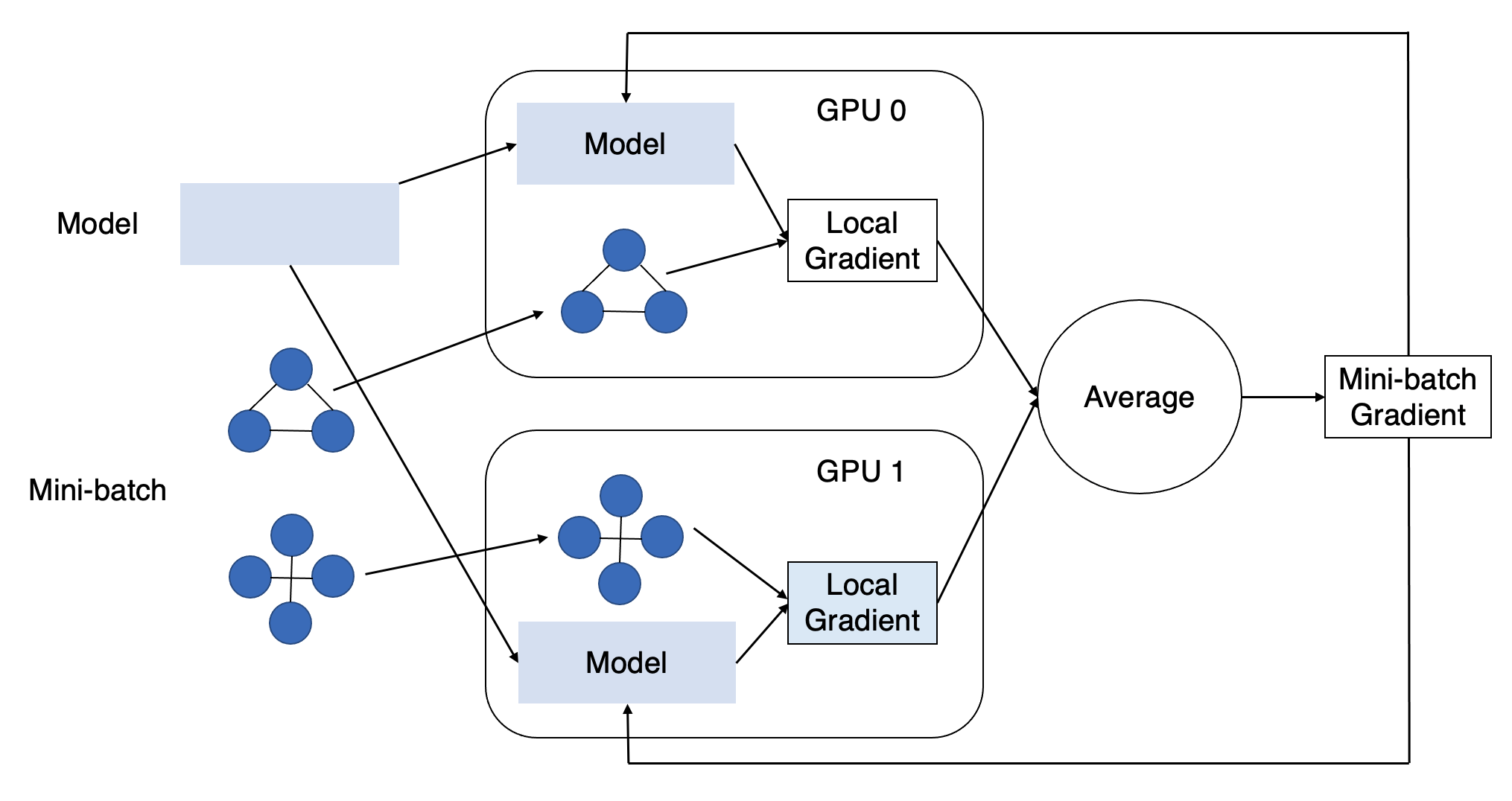
这就是本教程的核心内容。下面我们将通过完整的示例更详细地探讨它。
注意
请参阅 PyTorch 提供的此教程,了解使用 DistributedDataParallel 进行通用多 GPU 训练。
分布式进程组初始化
为了在多 GPU 训练中实现多个进程之间的通信,我们需要在每个进程开始时启动分布式后端。我们使用 world_size 来指代进程数,使用 rank 来指代进程 ID,进程 ID 应该是从 0 到 world_size - 1 的整数。
import os
os.environ["DGLBACKEND"] = "pytorch"
import torch.distributed as dist
def init_process_group(world_size, rank):
dist.init_process_group(
backend="gloo", # change to 'nccl' for multiple GPUs
init_method="tcp://127.0.0.1:12345",
world_size=world_size,
rank=rank,
)
数据加载器准备
我们将数据集分为训练、验证和测试子集。在数据集划分时,我们需要在所有进程中使用相同的随机种子以确保划分一致。我们遵循使用多个 GPU 进行训练和使用单个 GPU 进行评估的常见做法,因此仅在训练集的 GraphDataLoader() 中将 use_ddp 设置为 True,其中 ddp 代表 DistributedDataParallel()。
from dgl.data import split_dataset
from dgl.dataloading import GraphDataLoader
def get_dataloaders(dataset, seed, batch_size=32):
# Use a 80:10:10 train-val-test split
train_set, val_set, test_set = split_dataset(
dataset, frac_list=[0.8, 0.1, 0.1], shuffle=True, random_state=seed
)
train_loader = GraphDataLoader(
train_set, use_ddp=True, batch_size=batch_size, shuffle=True
)
val_loader = GraphDataLoader(val_set, batch_size=batch_size)
test_loader = GraphDataLoader(test_set, batch_size=batch_size)
return train_loader, val_loader, test_loader
模型初始化
在本教程中,我们使用简化的图同构网络 (GIN)。
import torch.nn as nn
import torch.nn.functional as F
from dgl.nn.pytorch import GINConv, SumPooling
class GIN(nn.Module):
def __init__(self, input_size=1, num_classes=2):
super(GIN, self).__init__()
self.conv1 = GINConv(
nn.Linear(input_size, num_classes), aggregator_type="sum"
)
self.conv2 = GINConv(
nn.Linear(num_classes, num_classes), aggregator_type="sum"
)
self.pool = SumPooling()
def forward(self, g, feats):
feats = self.conv1(g, feats)
feats = F.relu(feats)
feats = self.conv2(g, feats)
return self.pool(g, feats)
为确保所有进程的模型参数初始值相同,我们需要在模型初始化之前设置相同的随机种子。构造模型实例后,我们使用 DistributedDataParallel() 包装它。
import torch
from torch.nn.parallel import DistributedDataParallel
def init_model(seed, device):
torch.manual_seed(seed)
model = GIN().to(device)
if device.type == "cpu":
model = DistributedDataParallel(model)
else:
model = DistributedDataParallel(
model, device_ids=[device], output_device=device
)
return model
每个进程的主函数
按照单 GPU 设置中的方法定义模型评估函数。
def evaluate(model, dataloader, device):
model.eval()
total = 0
total_correct = 0
for bg, labels in dataloader:
bg = bg.to(device)
labels = labels.to(device)
# Get input node features
feats = bg.ndata.pop("attr")
with torch.no_grad():
pred = model(bg, feats)
_, pred = torch.max(pred, 1)
total += len(labels)
total_correct += (pred == labels).sum().cpu().item()
return 1.0 * total_correct / total
为每个进程定义运行函数。
from torch.optim import Adam
def run(rank, world_size, dataset, seed=0):
init_process_group(world_size, rank)
if torch.cuda.is_available():
device = torch.device("cuda:{:d}".format(rank))
torch.cuda.set_device(device)
else:
device = torch.device("cpu")
model = init_model(seed, device)
criterion = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=0.01)
train_loader, val_loader, test_loader = get_dataloaders(dataset, seed)
for epoch in range(5):
model.train()
# The line below ensures all processes use a different
# random ordering in data loading for each epoch.
train_loader.set_epoch(epoch)
total_loss = 0
for bg, labels in train_loader:
bg = bg.to(device)
labels = labels.to(device)
feats = bg.ndata.pop("attr")
pred = model(bg, feats)
loss = criterion(pred, labels)
total_loss += loss.cpu().item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss = total_loss
print("Loss: {:.4f}".format(loss))
val_acc = evaluate(model, val_loader, device)
print("Val acc: {:.4f}".format(val_acc))
test_acc = evaluate(model, test_loader, device)
print("Test acc: {:.4f}".format(test_acc))
dist.destroy_process_group()
最后,我们加载数据集并启动进程。
import torch.multiprocessing as mp
from dgl.data import GINDataset
def main():
if not torch.cuda.is_available():
print("No GPU found!")
return
num_gpus = torch.cuda.device_count()
dataset = GINDataset(name="IMDBBINARY", self_loop=False)
mp.spawn(run, args=(num_gpus, dataset), nprocs=num_gpus)
if __name__ == "__main__":
main()
No GPU found!
脚本总运行时间: (0 分 0.003 秒)