注意
跳转到末尾 下载完整的示例代码。
理解图注意力网络
作者: Hao Zhang, Mufei Li, Minjie Wang Zheng Zhang
警告
本教程旨在通过代码作为解释方式来深入理解论文。因此,该实现并未针对运行效率进行优化。如需推荐实现,请参考 官方示例。
在本教程中,您将学习图注意力网络 (GAT) 以及如何在 PyTorch 中实现它。您还将学习如何可视化和理解注意力机制学到了什么。
论文 图卷积网络 (GCN) 中描述的研究表明,结合局部图结构和节点级特征在节点分类任务中能取得良好的性能。然而,GCN 的聚合方式依赖于结构,这可能会损害其泛化能力。
一种解决方法是简单地对所有邻居节点的特征进行平均,如研究论文 GraphSAGE 中所述。然而,图注意力网络 提出了一种不同类型的聚合。GAT 使用注意力机制的风格,通过依赖于特征且独立于结构的归一化来加权邻居特征。
将注意力引入 GCN
GAT 和 GCN 之间的关键区别在于如何聚合来自一跳邻居的信息。
对于 GCN,图卷积操作产生邻居节点特征的归一化求和。
其中 \(\mathcal{N}(i)\) 是其一跳邻居的集合(若想包含 \(v_i\),只需给每个节点添加自环),\(c_{ij}=\sqrt{|\mathcal{N}(i)|}\sqrt{|\mathcal{N}(j)|}\) 是基于图结构的归一化常数,\(\sigma\) 是激活函数(GCN 使用 ReLU),\(W^{(l)}\) 是用于节点级特征转换的共享权重矩阵。论文 GraphSAGE 中提出的另一个模型采用了相同的更新规则,只是将 \(c_{ij}=|\mathcal{N}(i)|\)。
GAT 引入了注意力机制,取代了静态归一化的卷积操作。下面是从第 \(l\) 层的嵌入计算第 \(l+1\) 层的节点嵌入 \(h_i^{(l+1)}\) 的公式。
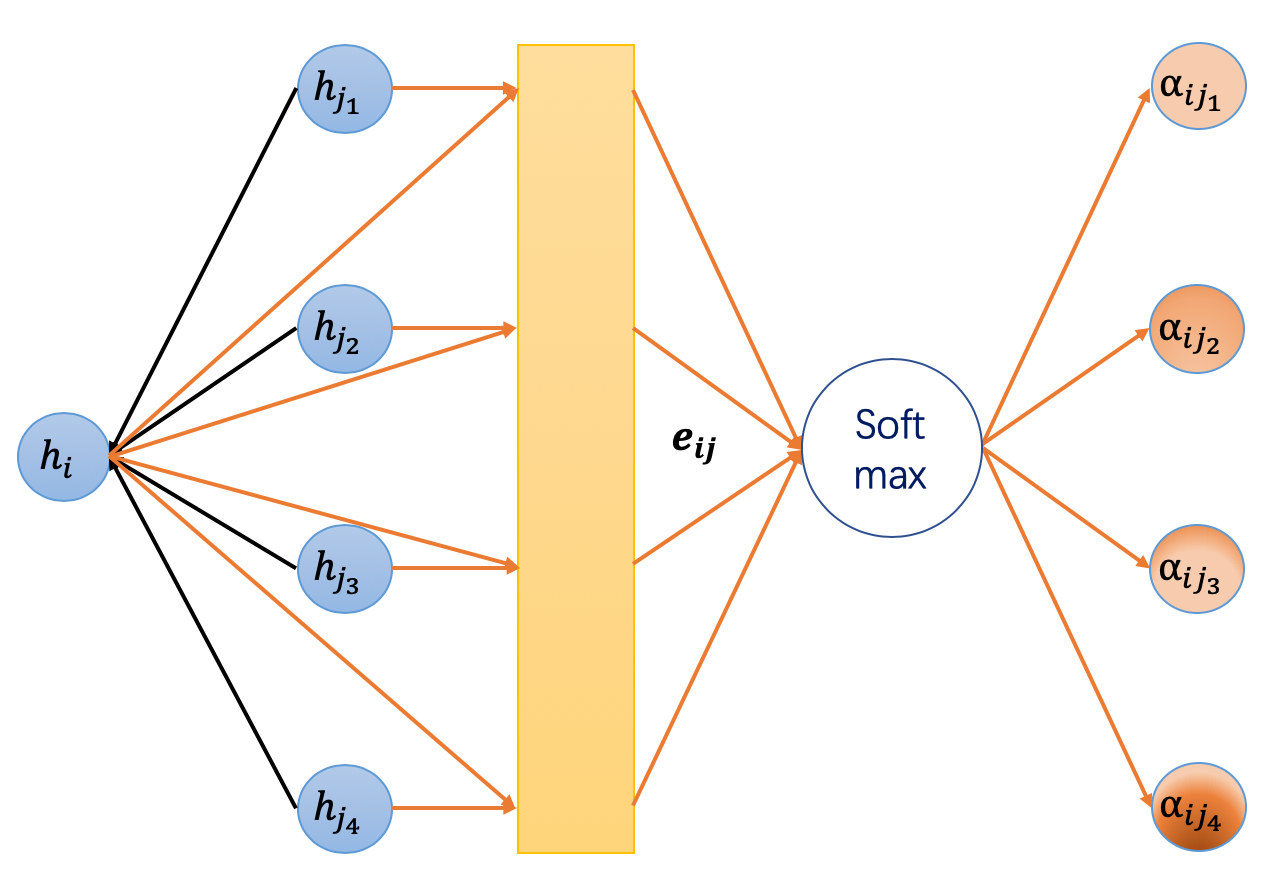
解释
公式 (1) 是对较低层嵌入 \(h_i^{(l)}\) 的线性变换,其中 \(W^{(l)}\) 是其可学习的权重矩阵。
公式 (2) 计算两个邻居之间的成对的 未归一化 注意力得分。在这里,它首先连接两个节点的 \(z\) 嵌入,其中 \(||\) 表示连接,然后将其与可学习的权重向量 \(\vec a^{(l)}\) 进行点积,最后应用 LeakyReLU。这种形式的注意力通常被称为 加性注意力,与 Transformer 模型中的点积注意力形成对比。
公式 (3) 应用 softmax 来归一化每个节点的入边上的注意力得分。
公式 (4) 类似于 GCN。来自邻居的嵌入被聚合在一起,并由注意力得分进行缩放。
论文中还有其他细节,例如 dropout 和 skip connections。为了简单起见,本教程省略了这些细节。要查看更多细节,请下载 完整示例。本质上,GAT 只是一个不同的聚合函数,它关注邻居的特征,而不是简单的平均聚合。
DGL 中的 GAT
DGL 在 dgl.nn.<backend> 子包下提供了 GAT 层的现成实现。只需按如下方式导入 GATConv。
import os
os.environ["DGLBACKEND"] = "pytorch"
读者可以跳过以下对实现的逐步解释,直接跳转到 将所有内容整合 部分查看训练和可视化结果。
首先,您可以对 DGL 中如何实现 GATLayer 模块有一个总体印象。在本节中,我们将逐一分解上面的四个公式。
注意
此处展示了如何从头开始实现 GAT。DGL 提供了更高效的 内置 GAT 层 模块。
import torch
import torch.nn as nn
import torch.nn.functional as F
from dgl.nn.pytorch import GATConv
class GATLayer(nn.Module):
def __init__(self, g, in_dim, out_dim):
super(GATLayer, self).__init__()
self.g = g
# equation (1)
self.fc = nn.Linear(in_dim, out_dim, bias=False)
# equation (2)
self.attn_fc = nn.Linear(2 * out_dim, 1, bias=False)
self.reset_parameters()
def reset_parameters(self):
"""Reinitialize learnable parameters."""
gain = nn.init.calculate_gain("relu")
nn.init.xavier_normal_(self.fc.weight, gain=gain)
nn.init.xavier_normal_(self.attn_fc.weight, gain=gain)
def edge_attention(self, edges):
# edge UDF for equation (2)
z2 = torch.cat([edges.src["z"], edges.dst["z"]], dim=1)
a = self.attn_fc(z2)
return {"e": F.leaky_relu(a)}
def message_func(self, edges):
# message UDF for equation (3) & (4)
return {"z": edges.src["z"], "e": edges.data["e"]}
def reduce_func(self, nodes):
# reduce UDF for equation (3) & (4)
# equation (3)
alpha = F.softmax(nodes.mailbox["e"], dim=1)
# equation (4)
h = torch.sum(alpha * nodes.mailbox["z"], dim=1)
return {"h": h}
def forward(self, h):
# equation (1)
z = self.fc(h)
self.g.ndata["z"] = z
# equation (2)
self.g.apply_edges(self.edge_attention)
# equation (3) & (4)
self.g.update_all(self.message_func, self.reduce_func)
return self.g.ndata.pop("h")
公式 (1)
第一个公式展示了线性变换。这很常见,可以使用 Pytorch 中的 torch.nn.Linear 轻松实现。
公式 (2)
未归一化注意力得分 \(e_{ij}\) 是使用相邻节点 \(i\) 和 \(j\) 的嵌入计算的。这表明注意力得分可以视为边数据,可以通过 apply_edges API 进行计算。apply_edges 的参数是一个 边 UDF,定义如下
def edge_attention(self, edges):
# edge UDF for equation (2)
z2 = torch.cat([edges.src["z"], edges.dst["z"]], dim=1)
a = self.attn_fc(z2)
return {"e": F.leaky_relu(a)}
在这里,与可学习权重向量 \(\vec{a^{(l)}}\) 的点积再次使用 PyTorch 的线性变换 attn_fc 实现。请注意,apply_edges 将把所有边数据 批量处理 到一个张量中,因此这里的 cat、attn_fc 会并行应用于所有边。
公式 (3) 和 (4)
类似于 GCN,使用 update_all API 触发所有节点上的消息传递。消息函数发送两个张量:源节点的变换后的 z 嵌入以及每条边上的未归一化注意力得分 e。Reduce 函数随后执行两个任务
使用 softmax 归一化注意力得分(公式 (3))。
聚合由注意力得分加权的邻居嵌入(公式 (4))。
这两个任务首先从邮箱获取数据,然后在消息批量处理的第二个维度 (dim=1`) 上对其进行操作。
def reduce_func(self, nodes):
# reduce UDF for equation (3) & (4)
# equation (3)
alpha = F.softmax(nodes.mailbox["e"], dim=1)
# equation (4)
h = torch.sum(alpha * nodes.mailbox["z"], dim=1)
return {"h": h}
多头注意力
类似于 ConvNet 中的多个通道,GAT 引入了 多头注意力 来丰富模型容量并稳定学习过程。每个注意力头都有自己的参数,其输出可以通过两种方式合并
或
其中 \(K\) 是头数。对于中间层可以使用连接,对于最终层可以使用平均。
使用上面定义的单头 GATLayer 作为下面 MultiHeadGATLayer 的构建块
class MultiHeadGATLayer(nn.Module):
def __init__(self, g, in_dim, out_dim, num_heads, merge="cat"):
super(MultiHeadGATLayer, self).__init__()
self.heads = nn.ModuleList()
for i in range(num_heads):
self.heads.append(GATLayer(g, in_dim, out_dim))
self.merge = merge
def forward(self, h):
head_outs = [attn_head(h) for attn_head in self.heads]
if self.merge == "cat":
# concat on the output feature dimension (dim=1)
return torch.cat(head_outs, dim=1)
else:
# merge using average
return torch.mean(torch.stack(head_outs))
将所有内容整合
现在,您可以定义一个两层的 GAT 模型。
class GAT(nn.Module):
def __init__(self, g, in_dim, hidden_dim, out_dim, num_heads):
super(GAT, self).__init__()
self.layer1 = MultiHeadGATLayer(g, in_dim, hidden_dim, num_heads)
# Be aware that the input dimension is hidden_dim*num_heads since
# multiple head outputs are concatenated together. Also, only
# one attention head in the output layer.
self.layer2 = MultiHeadGATLayer(g, hidden_dim * num_heads, out_dim, 1)
def forward(self, h):
h = self.layer1(h)
h = F.elu(h)
h = self.layer2(h)
return h
import networkx as nx
然后我们使用 DGL 的内置数据模块加载 Cora 数据集。
from dgl import DGLGraph
from dgl.data import citation_graph as citegrh
def load_cora_data():
data = citegrh.load_cora()
g = data[0]
mask = torch.BoolTensor(g.ndata["train_mask"])
return g, g.ndata["feat"], g.ndata["label"], mask
训练循环与 GCN 教程中完全相同。
import time
import numpy as np
g, features, labels, mask = load_cora_data()
# create the model, 2 heads, each head has hidden size 8
net = GAT(g, in_dim=features.size()[1], hidden_dim=8, out_dim=7, num_heads=2)
# create optimizer
optimizer = torch.optim.Adam(net.parameters(), lr=1e-3)
# main loop
dur = []
for epoch in range(30):
if epoch >= 3:
t0 = time.time()
logits = net(features)
logp = F.log_softmax(logits, 1)
loss = F.nll_loss(logp[mask], labels[mask])
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch >= 3:
dur.append(time.time() - t0)
print(
"Epoch {:05d} | Loss {:.4f} | Time(s) {:.4f}".format(
epoch, loss.item(), np.mean(dur)
)
)
NumNodes: 2708
NumEdges: 10556
NumFeats: 1433
NumClasses: 7
NumTrainingSamples: 140
NumValidationSamples: 500
NumTestSamples: 1000
Done loading data from cached files.
/opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/numpy/core/fromnumeric.py:3504: RuntimeWarning: Mean of empty slice.
return _methods._mean(a, axis=axis, dtype=dtype,
/opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages/numpy/core/_methods.py:129: RuntimeWarning: invalid value encountered in scalar divide
ret = ret.dtype.type(ret / rcount)
Epoch 00000 | Loss 1.9434 | Time(s) nan
Epoch 00001 | Loss 1.9414 | Time(s) nan
Epoch 00002 | Loss 1.9393 | Time(s) nan
Epoch 00003 | Loss 1.9373 | Time(s) 0.0998
Epoch 00004 | Loss 1.9352 | Time(s) 0.0962
Epoch 00005 | Loss 1.9332 | Time(s) 0.0944
Epoch 00006 | Loss 1.9311 | Time(s) 0.0955
Epoch 00007 | Loss 1.9290 | Time(s) 0.0948
Epoch 00008 | Loss 1.9269 | Time(s) 0.0946
Epoch 00009 | Loss 1.9249 | Time(s) 0.0948
Epoch 00010 | Loss 1.9228 | Time(s) 0.0945
Epoch 00011 | Loss 1.9207 | Time(s) 0.0955
Epoch 00012 | Loss 1.9186 | Time(s) 0.0951
Epoch 00013 | Loss 1.9165 | Time(s) 0.0952
Epoch 00014 | Loss 1.9144 | Time(s) 0.0950
Epoch 00015 | Loss 1.9122 | Time(s) 0.0944
Epoch 00016 | Loss 1.9101 | Time(s) 0.0941
Epoch 00017 | Loss 1.9080 | Time(s) 0.0939
Epoch 00018 | Loss 1.9058 | Time(s) 0.0941
Epoch 00019 | Loss 1.9036 | Time(s) 0.0938
Epoch 00020 | Loss 1.9015 | Time(s) 0.0939
Epoch 00021 | Loss 1.8993 | Time(s) 0.0937
Epoch 00022 | Loss 1.8971 | Time(s) 0.0937
Epoch 00023 | Loss 1.8949 | Time(s) 0.0939
Epoch 00024 | Loss 1.8927 | Time(s) 0.0941
Epoch 00025 | Loss 1.8904 | Time(s) 0.0945
Epoch 00026 | Loss 1.8882 | Time(s) 0.0945
Epoch 00027 | Loss 1.8859 | Time(s) 0.0943
Epoch 00028 | Loss 1.8837 | Time(s) 0.0945
Epoch 00029 | Loss 1.8814 | Time(s) 0.0945
可视化和理解学习到的注意力
Cora
下表总结了在 Cora 数据集上,论文 GAT 论文 中报告的以及使用 DGL 实现获得的模型性能。
模型 |
准确率 |
|---|---|
GCN (论文) |
\(81.4\pm 0.5%\) |
GCN (dgl) |
\(82.05\pm 0.33%\) |
GAT (论文) |
\(83.0\pm 0.7%\) |
GAT (dgl) |
\(83.69\pm 0.529%\) |
我们的模型学习到了什么样的注意力分布?
由于注意力权重 \(a_{ij}\) 与边相关联,您可以通过给边着色来将其可视化。下面您可以选择 Cora 的一个子图,并绘制最后一个 GATLayer 的注意力权重。节点根据其标签着色,而边则根据注意力权重的大小着色,右侧的颜色条可供参考。

您可以看到模型似乎学习到了不同的注意力权重。为了更彻底地理解分布,可以测量注意力分布的 熵)。对于任何节点 \(i\),\(\{\alpha_{ij}\}_{j\in\mathcal{N}(i)}\) 构成了一个离散概率分布,分布在所有邻居上,其熵由下式给出
低熵意味着高度集中,反之亦然。熵为 0 意味着所有注意力都集中在一个源节点上。均匀分布的熵最高,为 \(\log(\mathcal{N}(i))\)。理想情况下,您希望看到模型学习到的分布具有较低的熵(即,一个或两个邻居比其他邻居重要得多)。
请注意,由于节点的度数可能不同,最大熵也会不同。因此,我们绘制了整个图中所有节点的熵值的聚合直方图。下面是每个注意力头学习到的注意力直方图。
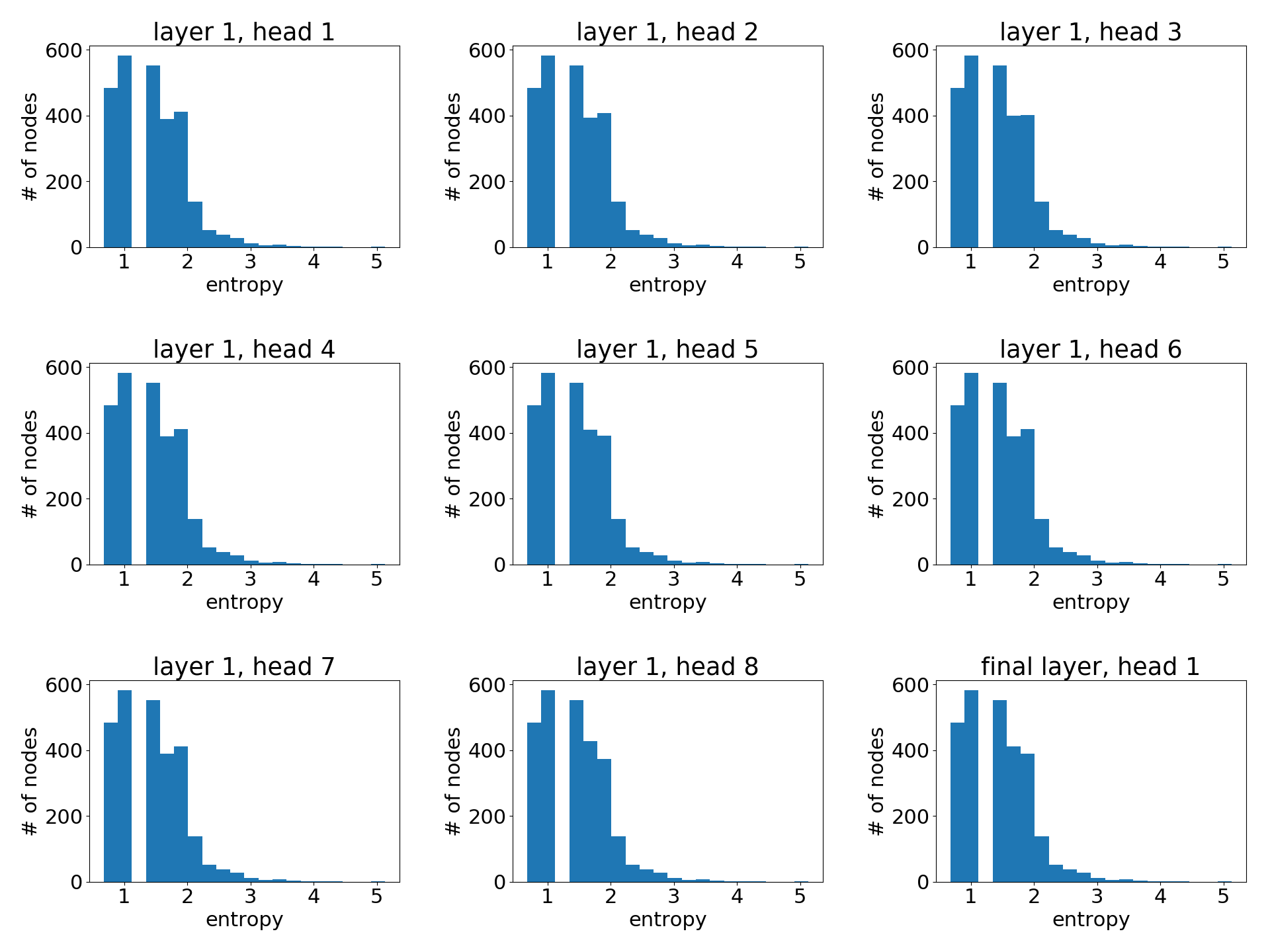
作为参考,这是所有节点都具有均匀注意力权重分布时的直方图。
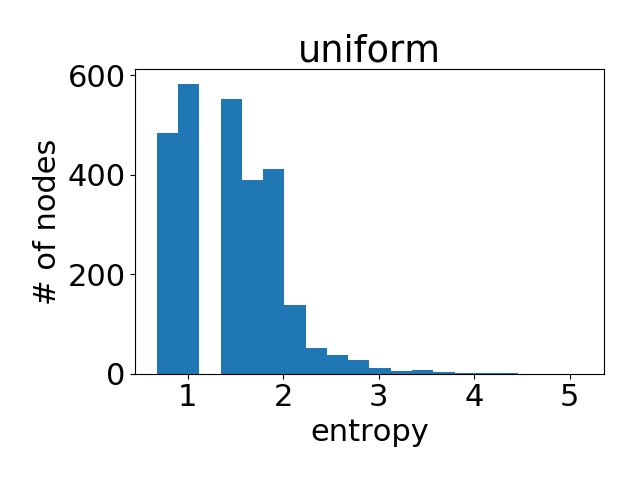
可以看出,学习到的注意力值与均匀分布非常相似(即所有邻居同等重要)。这部分解释了为什么 GAT 在 Cora 上的性能与 GCN 接近(根据 作者报告的结果,100 次运行平均的准确率差异小于 2%)。注意力在这种情况下影响不大,因为它没有多少区分度。
这是否意味着注意力机制没有用? 不是!不同的数据集会表现出完全不同的模式,您接下来就会看到。
蛋白质-蛋白质相互作用 (PPI) 网络
此处使用的 PPI 数据集包含 \(24\) 个图,对应于不同的人体组织。节点最多可以有 \(121\) 种标签,因此节点的标签表示为一个大小为 \(121\) 的二进制张量。任务是预测节点标签。
使用 \(20\) 个图用于训练,\(2\) 个用于验证,\(2\) 个用于测试。每个图的平均节点数为 \(2372\)。每个节点具有 \(50\) 个特征,由位置基因集、基序基因集和免疫学特征组成。关键的是,测试图在训练期间完全未被观察到,这是一种称为“归纳学习”的设置。
比较 GAT 和 GCN 在此任务上进行 \(10\) 次随机运行的性能,并在验证集上使用超参数搜索来找到最佳模型。
模型 |
F1 分数 (micro) |
|---|---|
GAT |
\(0.975 \pm 0.006\) |
GCN |
\(0.509 \pm 0.025\) |
论文 |
\(0.973 \pm 0.002\) |
上表是此实验的结果,我们使用 micro F1 分数 来评估模型性能。
注意
下面是 F1 分数的计算过程
\(TP_{t}\) 表示同时具有标签 \(t\) 且被预测具有标签 \(t\) 的节点数
\(FP_{t}\) 表示不具有标签 \(t\) 但被预测具有标签 \(t\) 的节点数
\(FN_{t}\) 表示被标记为 \(t\) 但被预测为其他标签的输出类别数。
\(n\) 是标签的数量,在本例中即为 \(121\)。
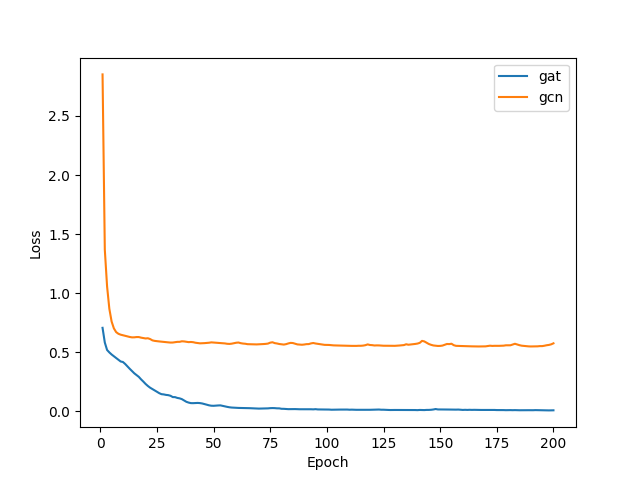
训练期间,使用 BCEWithLogitsLoss 作为损失函数。下面展示了 GAT 和 GCN 的学习曲线;显而易见的是 GAT 相对于 GCN 具有显著的性能优势。
如前所述,您可以通过展示节点级注意力熵的直方图来对学习到的注意力进行统计理解。下面是不同注意力层学习到的注意力直方图。
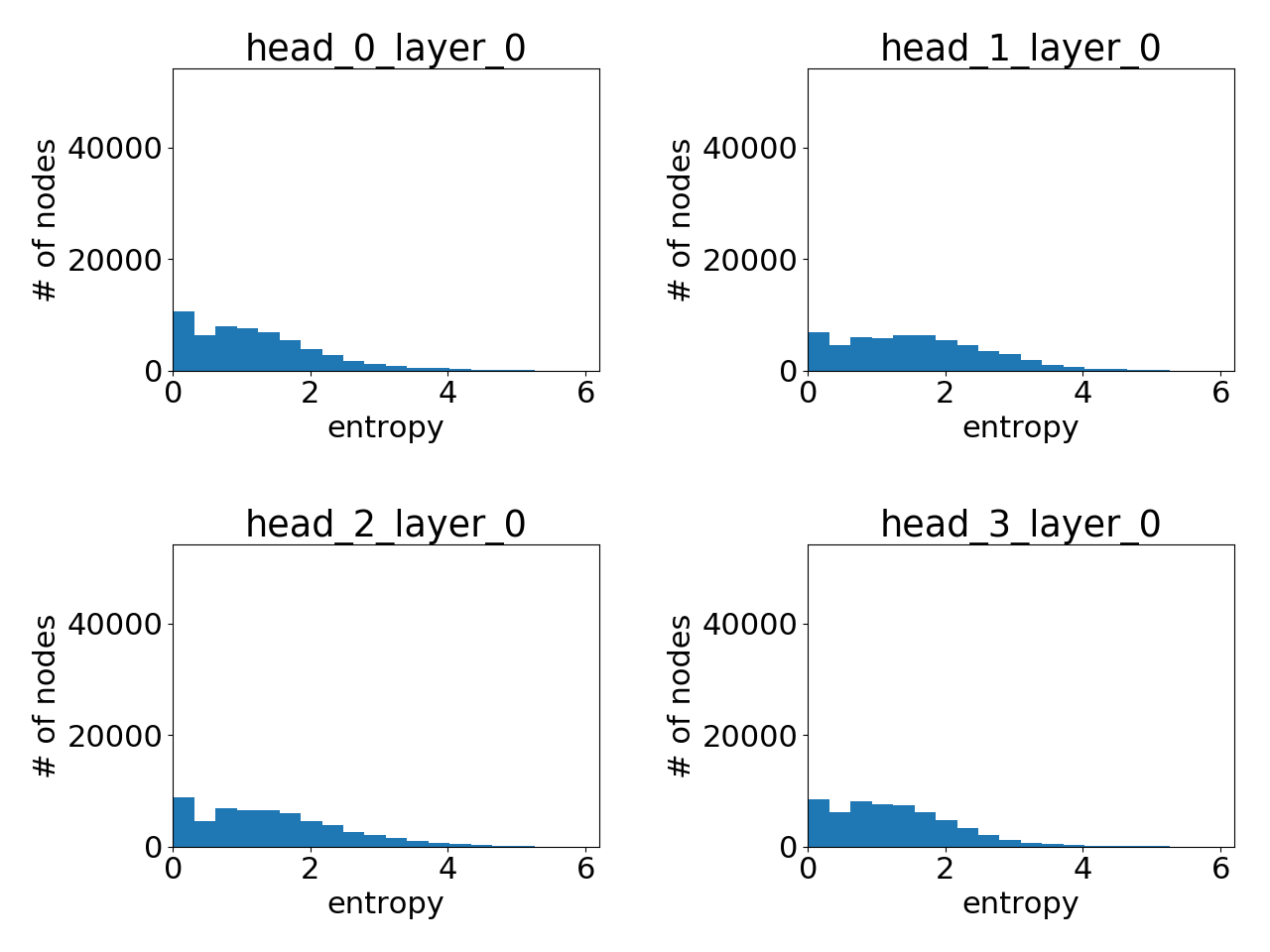
第 1 层学习到的注意力
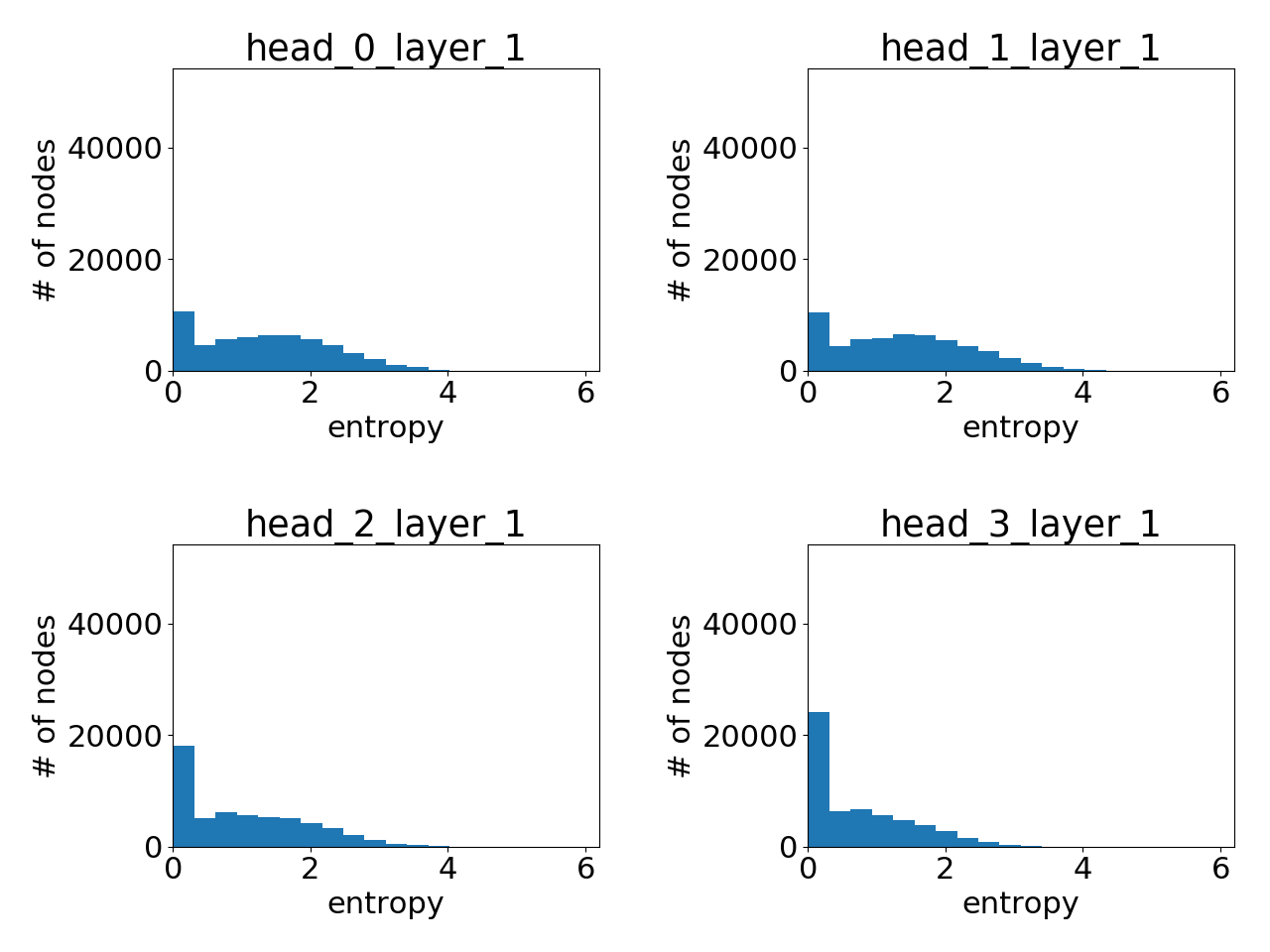
第 2 层学习到的注意力
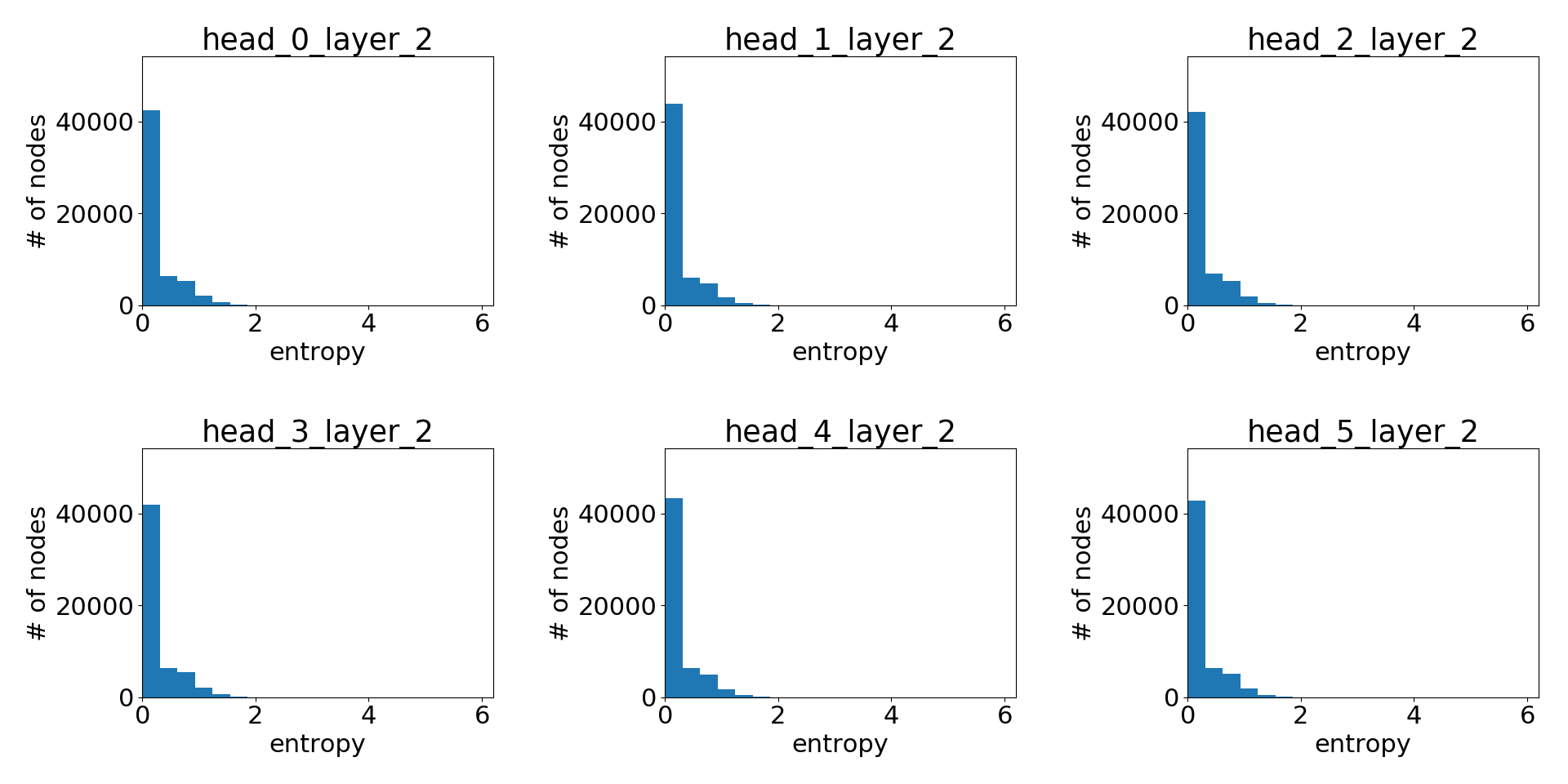
最终层学习到的注意力
再次,与均匀分布进行比较
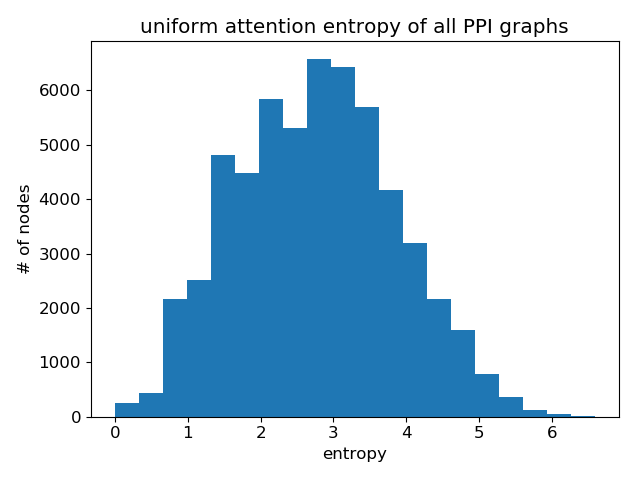
显然,GAT 确实学习到了尖锐的注意力权重!层与层之间也存在一个清晰的模式:层数越高,注意力越尖锐。
与 Cora 数据集上 GAT 的提升微乎其微不同,对于 PPI 数据集,GAT 与 GAT 论文 中比较的其他 GNN 变体之间存在显著的性能差距(至少 20%),并且两者之间的注意力分布明显不同。虽然这值得进一步研究,但一个直接的结论是,GAT 的优势可能更多在于其处理邻域结构更复杂的图的能力。
下一步是什么?
至此,您已经了解了如何使用 DGL 实现 GAT。还有一些细节缺失,例如 dropout、skip connections 和超参数调优,这些是不涉及 DGL 相关概念的实践。有关更多信息,请查看完整示例。
请参阅优化的 完整示例。
下一个教程描述了如何通过并行化多个注意力头和 SPMV 优化来加速 GAT 模型。
脚本总运行时间: (0 分 2.888 秒)