节点分类
本教程展示了如何使用 DGL 的邻居采样组件在单个 GPU 上训练多层 GraphSAGE 用于节点分类。我们在 Open Graph Benchmark (OGB) 提供的 ogbn-arxiv 数据集上进行训练。该数据集包含大约 17 万个节点和 100 万条边。
![]()
在本教程结束时,你将能够
使用 DGL 的邻居采样组件,在单个 GPU 上训练 GNN 模型进行节点分类。
安装 DGL 包
[1]:
# Install required packages.
import os
import torch
import numpy as np
os.environ['TORCH'] = torch.__version__
os.environ['DGLBACKEND'] = "pytorch"
# Install the CPU version in default. If you want to install CUDA version,
# please refer to https://dgl.ac.cn/pages/start.html and change runtime type
# accordingly.
device = torch.device("cpu")
!pip install --pre dgl -f https://data.dgl.ai/wheels-test/repo.html
try:
import dgl
import dgl.graphbolt as gb
installed = True
except ImportError as error:
installed = False
print(error)
print("DGL installed!" if installed else "DGL not found!")
Looking in links: https://data.dgl.ai/wheels-test/repo.html
Requirement already satisfied: dgl in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (2.2a240410)
Requirement already satisfied: numpy>=1.14.0 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from dgl) (1.26.4)
Requirement already satisfied: scipy>=1.1.0 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from dgl) (1.14.1)
Requirement already satisfied: networkx>=2.1 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from dgl) (3.4.2)
Requirement already satisfied: requests>=2.19.0 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from dgl) (2.32.3)
Requirement already satisfied: tqdm in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from dgl) (4.66.6)
Requirement already satisfied: psutil>=5.8.0 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from dgl) (6.1.0)
Requirement already satisfied: torchdata>=0.5.0 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from dgl) (0.9.0)
Requirement already satisfied: pandas in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from dgl) (2.2.3)
Requirement already satisfied: charset-normalizer<4,>=2 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from requests>=2.19.0->dgl) (3.4.0)
Requirement already satisfied: idna<4,>=2.5 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from requests>=2.19.0->dgl) (3.10)
Requirement already satisfied: urllib3<3,>=1.21.1 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from requests>=2.19.0->dgl) (2.2.3)
Requirement already satisfied: certifi>=2017.4.17 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from requests>=2.19.0->dgl) (2024.8.30)
Requirement already satisfied: torch>=2 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from torchdata>=0.5.0->dgl) (2.1.0+cpu)
Requirement already satisfied: python-dateutil>=2.8.2 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from pandas->dgl) (2.9.0.post0)
Requirement already satisfied: pytz>=2020.1 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from pandas->dgl) (2024.2)
Requirement already satisfied: tzdata>=2022.7 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from pandas->dgl) (2024.2)
Requirement already satisfied: six>=1.5 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from python-dateutil>=2.8.2->pandas->dgl) (1.16.0)
Requirement already satisfied: filelock in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from torch>=2->torchdata>=0.5.0->dgl) (3.16.1)
Requirement already satisfied: typing-extensions in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from torch>=2->torchdata>=0.5.0->dgl) (4.12.2)
Requirement already satisfied: sympy in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from torch>=2->torchdata>=0.5.0->dgl) (1.13.3)
Requirement already satisfied: jinja2 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from torch>=2->torchdata>=0.5.0->dgl) (3.1.4)
Requirement already satisfied: fsspec in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from torch>=2->torchdata>=0.5.0->dgl) (2024.10.0)
Requirement already satisfied: MarkupSafe>=2.0 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from jinja2->torch>=2->torchdata>=0.5.0->dgl) (3.0.2)
Requirement already satisfied: mpmath<1.4,>=1.1.0 in /opt/conda/envs/dgl-dev-cpu/lib/python3.10/site-packages (from sympy->torch>=2->torchdata>=0.5.0->dgl) (1.3.0)
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager, possibly rendering your system unusable.It is recommended to use a virtual environment instead: https://pip.pypa.org.cn/warnings/venv. Use the --root-user-action option if you know what you are doing and want to suppress this warning.
DGL installed!
加载数据集
ogbn-arxiv 在 GraphBolt 中已经被准备为 BuiltinDataset。
[2]:
dataset = gb.BuiltinDataset("ogbn-arxiv-seeds").load()
Downloading datasets/ogbn-arxiv-seeds.zip from https://data.dgl.ai/dataset/graphbolt/ogbn-arxiv-seeds.zip...
Extracting file to datasets
The dataset is already preprocessed.
数据集包含图、特征和任务。你可以从任务中获取训练集、验证集和测试集。种子节点及其对应的标签已经存储在每个训练集、验证集和测试集中。其他元数据(如类别数量)也存储在任务中。在此数据集中,只有一个任务:节点分类。
[3]:
graph = dataset.graph.to(device)
feature = dataset.feature.to(device)
train_set = dataset.tasks[0].train_set
valid_set = dataset.tasks[0].validation_set
test_set = dataset.tasks[0].test_set
task_name = dataset.tasks[0].metadata["name"]
num_classes = dataset.tasks[0].metadata["num_classes"]
print(f"Task: {task_name}. Number of classes: {num_classes}")
Task: node_classification. Number of classes: 40
DGL 如何处理计算依赖¶
单个节点消息传递的计算依赖可以描述为一系列消息流图 (MFG)。
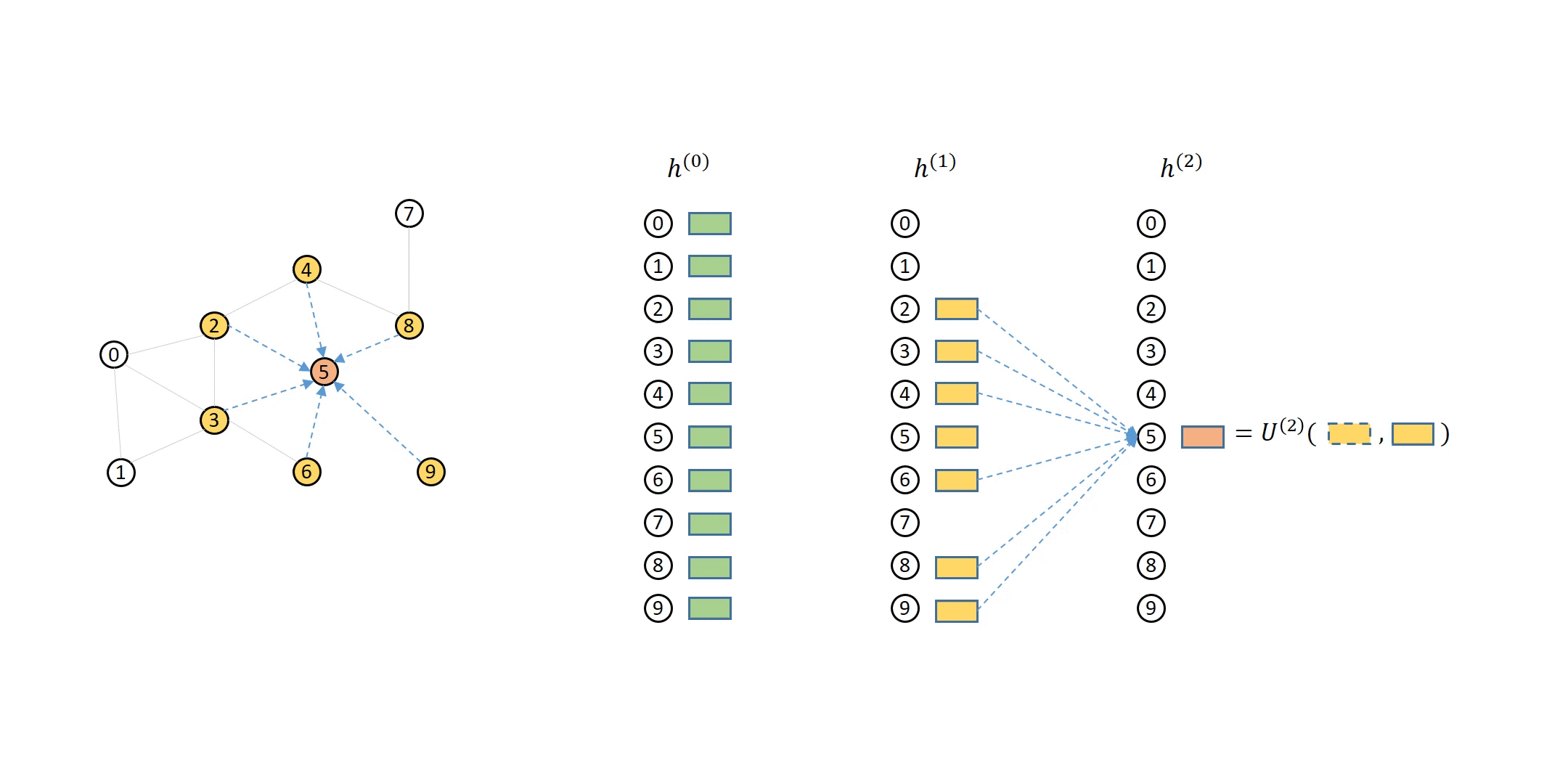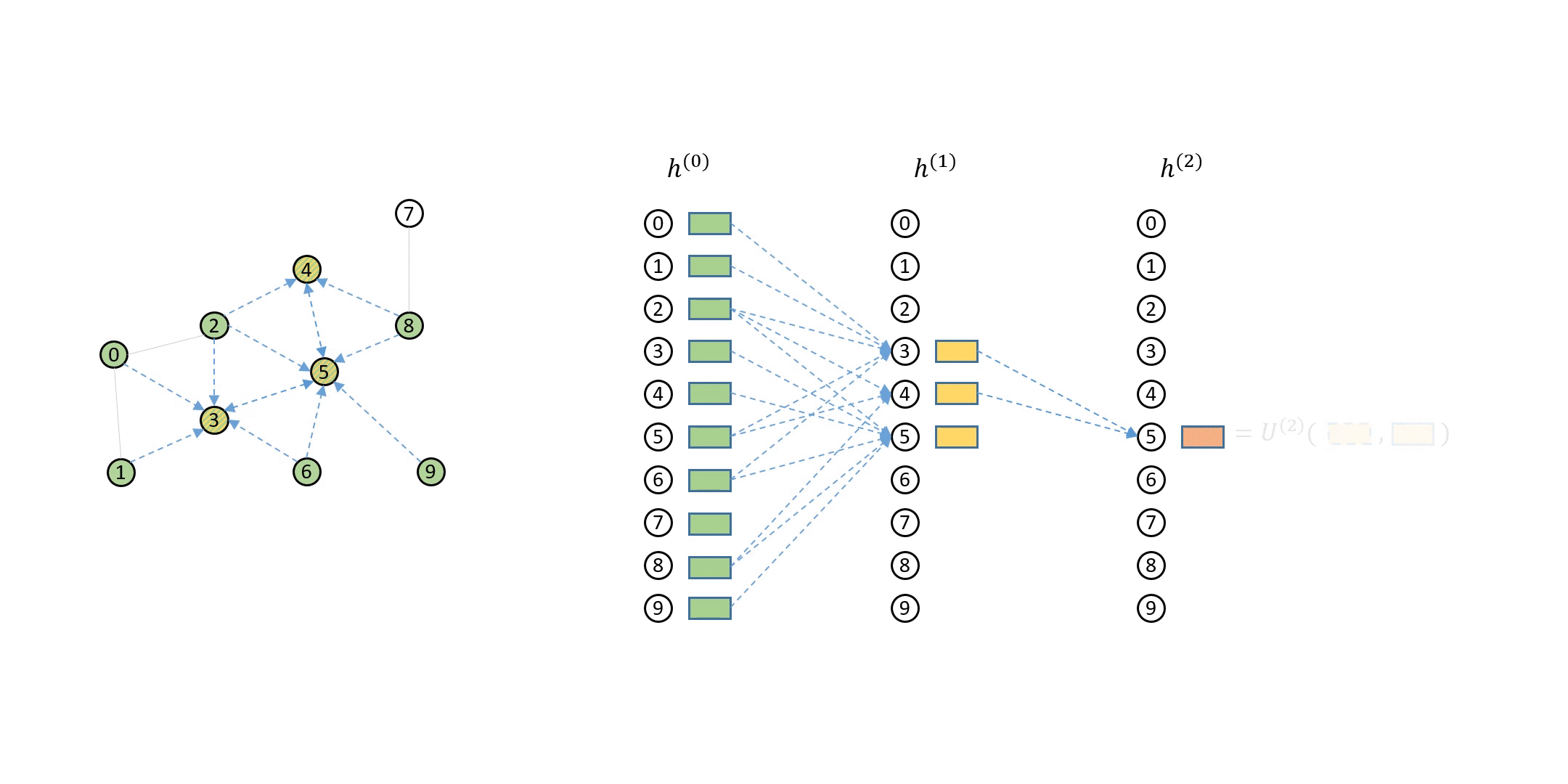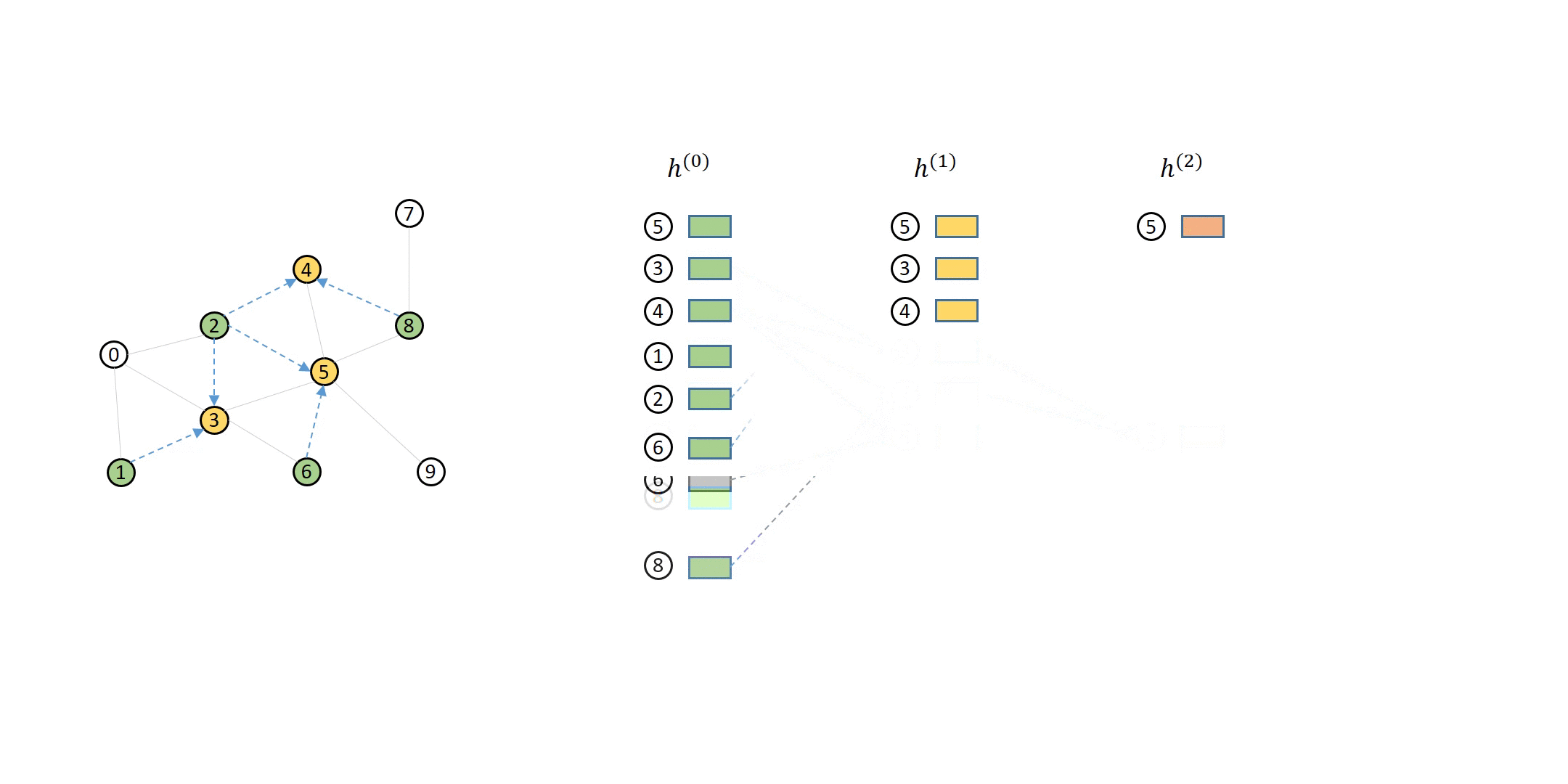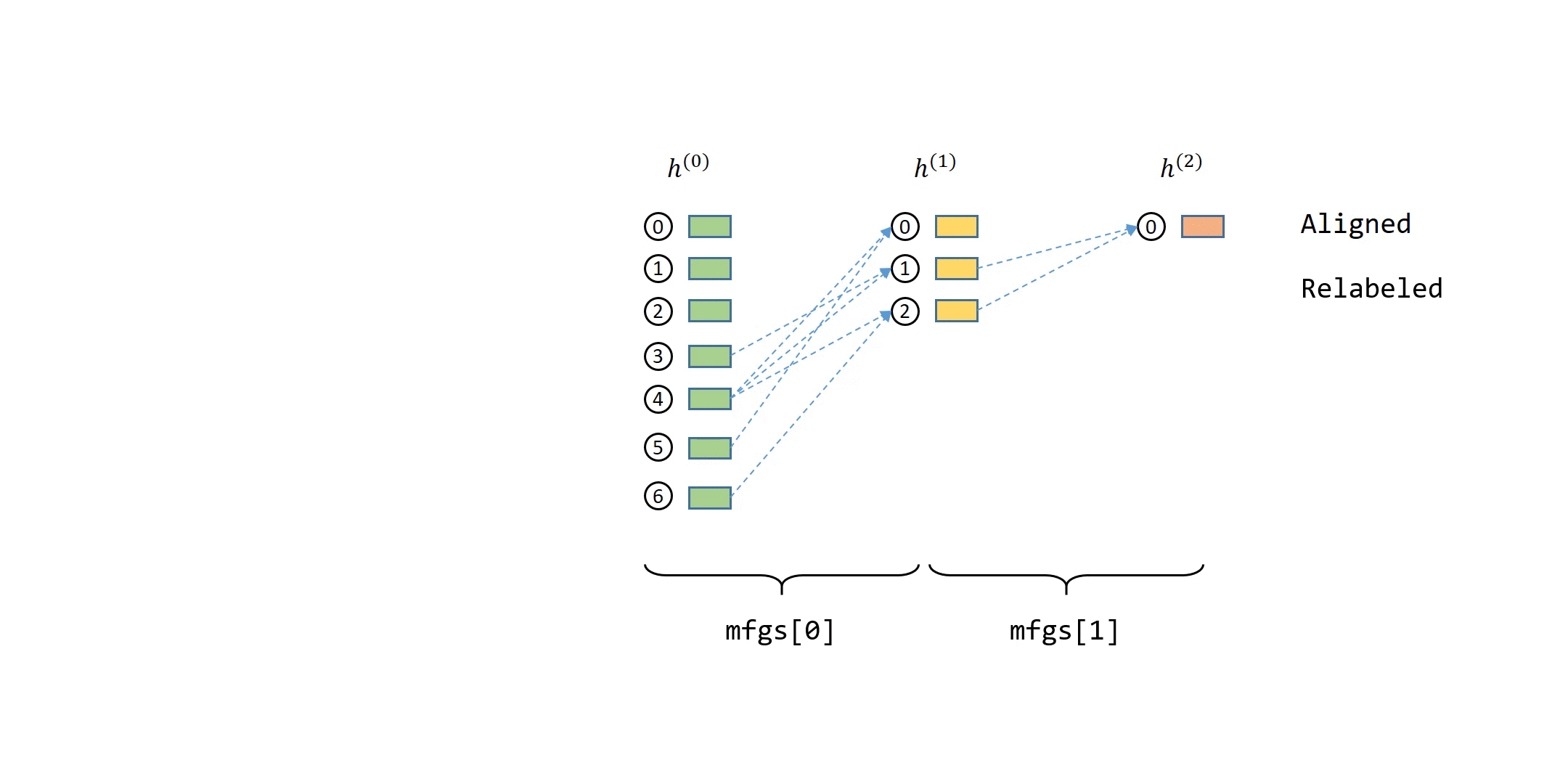
在 DGL 中定义邻居采样器和数据加载器
DGL 提供了工具来以 mini-batch 的方式迭代数据集,同时生成计算其输出所需的计算依赖(如上述 MFG 所示)。对于节点分类,你可以使用 dgl.graphbolt.DataLoader 来迭代数据集。它接受一个数据管道 (data pipe),该管道生成节点的 mini-batch 及其标签,为每个节点采样邻居,并以 MFG 的形式生成计算依赖。它也支持特征获取、块创建和复制到目标设备。所有这些操作在数据管道中被分成独立的阶段,这样你就可以通过插入自己的操作来定制数据管道。
假设每个节点在每一层都会从 4 个邻居收集消息。定义数据加载器和邻居采样的代码如下所示。
[4]:
def create_dataloader(itemset, shuffle):
datapipe = gb.ItemSampler(itemset, batch_size=1024, shuffle=shuffle)
datapipe = datapipe.copy_to(device)
datapipe = datapipe.sample_neighbor(graph, [4, 4])
datapipe = datapipe.fetch_feature(feature, node_feature_keys=["feat"])
return gb.DataLoader(datapipe)
你可以迭代数据加载器,每次迭代会产生一个 MiniBatch 对象。
[5]:
data = next(iter(create_dataloader(train_set, shuffle=True)))
print(data)
MiniBatch(seeds=tensor([ 65183, 163561, 76677, ..., 12099, 16843, 4191]),
sampled_subgraphs=[SampledSubgraphImpl(sampled_csc=CSCFormatBase(indptr=tensor([ 0, 4, 8, ..., 14635, 14639, 14643], dtype=torch.int32),
indices=tensor([ 1502, 1024, 3847, ..., 3846, 11707, 11708], dtype=torch.int32),
),
original_row_node_ids=tensor([ 65183, 163561, 76677, ..., 82248, 65213, 9690]),
original_edge_ids=tensor([ 962702, 978322, 1499230, ..., 2465385, 894690, 135709]),
original_column_node_ids=tensor([ 65183, 163561, 76677, ..., 29265, 6099, 149787]),
),
SampledSubgraphImpl(sampled_csc=CSCFormatBase(indptr=tensor([ 0, 4, 8, ..., 3655, 3658, 3662], dtype=torch.int32),
indices=tensor([1024, 0, 1025, ..., 3845, 3846, 1023], dtype=torch.int32),
),
original_row_node_ids=tensor([ 65183, 163561, 76677, ..., 29265, 6099, 149787]),
original_edge_ids=tensor([ 978322, 2380781, 2044949, ..., 87067, 2052817, 2319789]),
original_column_node_ids=tensor([ 65183, 163561, 76677, ..., 12099, 16843, 4191]),
)],
node_features={'feat': tensor([[-0.0422, -0.0014, -0.1854, ..., 0.0134, -0.0261, -0.0950],
[-0.0507, 0.0820, -0.2800, ..., 0.0044, -0.0816, 0.1165],
[-0.2002, 0.0058, -0.3861, ..., 0.2154, 0.1007, -0.0761],
...,
[-0.0414, -0.0854, -0.1887, ..., 0.1158, -0.0962, -0.0719],
[-0.0779, 0.0138, -0.1698, ..., 0.0613, -0.0654, -0.1182],
[-0.0545, -0.0352, -0.0440, ..., 0.3083, -0.0255, -0.2265]])},
labels=tensor([19, 34, 27, ..., 28, 2, 28]),
input_nodes=tensor([ 65183, 163561, 76677, ..., 82248, 65213, 9690]),
indexes=None,
edge_features=[{},
{}],
compacted_seeds=None,
blocks=[Block(num_src_nodes=11709, num_dst_nodes=3847, num_edges=14643),
Block(num_src_nodes=3847, num_dst_nodes=1024, num_edges=3662)],
)
你可以从 MFG 中获取输入节点的 ID。
[6]:
mfgs = data.blocks
input_nodes = mfgs[0].srcdata[dgl.NID]
print(f"Input nodes: {input_nodes}.")
Input nodes: tensor([ 65183, 163561, 76677, ..., 82248, 65213, 9690]).
定义模型
让我们考虑训练一个带有邻居采样的 2 层 GraphSAGE。模型可以写成如下形式
[7]:
import torch.nn as nn
import torch.nn.functional as F
from dgl.nn import SAGEConv
class Model(nn.Module):
def __init__(self, in_feats, h_feats, num_classes):
super(Model, self).__init__()
self.conv1 = SAGEConv(in_feats, h_feats, aggregator_type="mean")
self.conv2 = SAGEConv(h_feats, num_classes, aggregator_type="mean")
self.h_feats = h_feats
def forward(self, mfgs, x):
h = self.conv1(mfgs[0], x)
h = F.relu(h)
h = self.conv2(mfgs[1], h)
return h
in_size = feature.size("node", None, "feat")[0]
model = Model(in_size, 64, num_classes).to(device)
定义训练循环
以下代码初始化模型并定义优化器。
[8]:
opt = torch.optim.Adam(model.parameters())
在计算验证分数以进行模型选择时,通常你也可以进行邻居采样。我们可以重用 create_dataloader 函数来创建两个独立的数据加载器,一个用于训练,一个用于验证。
[9]:
train_dataloader = create_dataloader(train_set, shuffle=True)
valid_dataloader = create_dataloader(valid_set, shuffle=False)
import sklearn.metrics
以下是一个训练循环,它在每个 epoch 进行验证。它还将具有最佳验证精度的模型保存到文件中。
[10]:
from tqdm.auto import tqdm
for epoch in range(10):
model.train()
with tqdm(train_dataloader) as tq:
for step, data in enumerate(tq):
x = data.node_features["feat"]
labels = data.labels
predictions = model(data.blocks, x)
loss = F.cross_entropy(predictions, labels)
opt.zero_grad()
loss.backward()
opt.step()
accuracy = sklearn.metrics.accuracy_score(
labels.cpu().numpy(),
predictions.argmax(1).detach().cpu().numpy(),
)
tq.set_postfix(
{"loss": "%.03f" % loss.item(), "acc": "%.03f" % accuracy},
refresh=False,
)
model.eval()
predictions = []
labels = []
with tqdm(valid_dataloader) as tq, torch.no_grad():
for data in tq:
x = data.node_features["feat"]
labels.append(data.labels.cpu().numpy())
predictions.append(model(data.blocks, x).argmax(1).cpu().numpy())
predictions = np.concatenate(predictions)
labels = np.concatenate(labels)
accuracy = sklearn.metrics.accuracy_score(labels, predictions)
print("Epoch {} Validation Accuracy {}".format(epoch, accuracy))
Epoch 0 Validation Accuracy 0.47280110070807746
Epoch 1 Validation Accuracy 0.5744152488338535
Epoch 2 Validation Accuracy 0.6083090036578409
Epoch 3 Validation Accuracy 0.6244169267425081
Epoch 4 Validation Accuracy 0.633813215208564
Epoch 5 Validation Accuracy 0.6389476156918017
Epoch 6 Validation Accuracy 0.6423705493472935
Epoch 7 Validation Accuracy 0.6425718983858518
Epoch 8 Validation Accuracy 0.6542501426222357
Epoch 9 Validation Accuracy 0.6531091647370717
结论
在本教程中,你学习了如何使用邻居采样训练多层 GraphSAGE。