
在CPU上使用BFloat16数据类型加速GNN训练
图神经网络(GNN)在各种工业任务中取得了最先进的性能。然而,大多数GNN操作受内存限制,需要大量的RAM。为了解决这个问题,提出了一种使用小数据类型减少张量大小的众所周知技术,用于优化在支持Bfloat16的Intel® Xeon® 可扩展处理器上进行GNN训练的内存效率。所提出的方法可以在各种GNN模型上实现出色的优化,覆盖广泛的数据集,训练速度提高了5倍。
Bfloat16数据类型
Bfloat16是一种半精度数据类型。它与默认的float数据类型仅在尾数长度上不同,Bfloat16的尾数长度为7位,而float为23位。
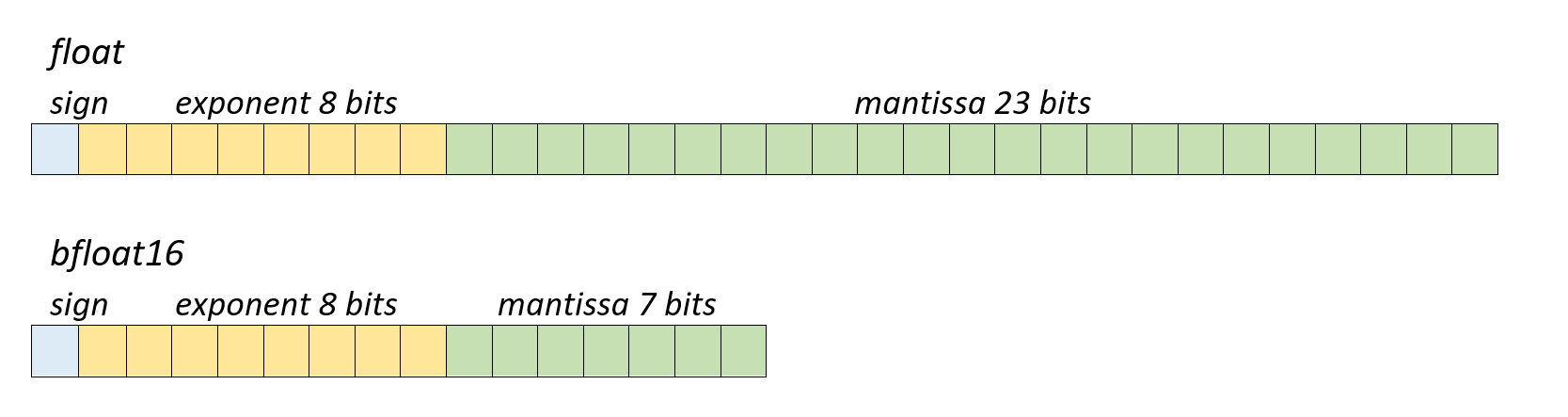
Bfloat16由Google Brain团队开发,目前在DNN和其他AI应用中广泛使用。从GPU和AI加速器到CPU,许多设备原生支持bfloat16。甚至GCC和LLVM等编译器在最新的C/C++标准中也启用了此数据类型。根据Google Brain团队的观点,指数对于训练和ML操作更有价值,因此减少尾数位可以在保持模型精度的同时,提供与其他半精度数据类型相同的性能。使用bfloat16数据类型的另一个优点是bfloat16和float之间转换的简易性。
Bfloat16 CPU加速
从第三代Intel® Xeon® 可扩展处理器(代号Cooper Lake)开始,x86 CPU原生支持bfloat16。这是通过Intel® 高级矢量扩展指令集-512(Intel® AVX-512):AVX512_BF16矢量指令集实现的,该指令集与其他AVX512指令一样,提供了基本操作:点积和转换函数。在最新的第四代Intel® Xeon® 可扩展处理器(代号Sapphire Rapids)中,引入了Intel® AMX指令集,以进一步提升16位和8位矩阵的性能。该指令集添加了“tile”指令,这些指令在特殊的“tile”二维寄存器上操作。目前,该指令集仅支持tile矩阵乘法单元(TMUL),可以执行bfloat16和int8数据类型的矩阵乘法。在下一代Intel Xeon处理器中,从Granite Rapids开始,除了bfloat16之外,还将支持fp16。
DGL中的Bfloat16支持
最近,DGL库添加了bfloat16支持(从适用于Nvidia GPU的DGL版本1.0.0和适用于CPU的DGL版本1.1.0开始),因此可以在CPU和GPU设备上进行模型训练和推理时使用它。以下是一些DGL API示例,可以帮助将图和模型转换为bfloat16数据类型。
# Convert graph, model, and graph features to bfloat16
g = dgl.to_bfloat16(g)
feat = feat.to(dtype=torch.bfloat16)
model = model.to(dtype=torch.bfloat16)
以下示例使用提供的API训练GraphSAGE,并使用bfloat16数据类型
import torch
import torch.nn as nn
import torch.nn.functional as F
import dgl
from dgl.data import CiteseerGraphDataset
from dgl.nn import SAGEConv
from dgl.transforms import AddSelfLoop
class SAGE(nn.Module):
def __init__(self, in_size, hid_size, out_size):
super().__init__()
self.layers = nn.ModuleList()
# two-layer SAGE
self.layers.append(SAGEConv(in_size, hid_size, "gcn"))
self.layers.append(SAGEConv(hid_size, out_size, "gcn"))
self.dropout = nn.Dropout(0.5)
def forward(self, graph, features):
h = self.dropout(features)
for l, layer in enumerate(self.layers):
h = layer(graph, h)
if l != len(self.layers) - 1:
h = F.relu(h)
h = self.dropout(h)
return h
# Data loading
transform = AddSelfLoop()
data = CiteseerGraphDataset(transform=transform)
g = data[0]
g = g.int()
train_mask = g.ndata['train_mask']
feat = g.ndata['feat']
label = g.ndata['label']
in_size = feat.shape[1]
hid_size = 16
out_size = data.num_classes
model = SAGE(in_size, hid_size, out_size)
# Convert model and graph to bfloat16
g = dgl.to_bfloat16(g)
feat = feat.to(dtype=torch.bfloat16)
model = model.to(dtype=torch.bfloat16)
model.train()
# Create optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=1e-2, weight_decay=5e-4)
loss_fcn = nn.CrossEntropyLoss()
for epoch in range(100):
logits = model(g, feat)
loss = loss_fcn(logits[train_mask], label[train_mask])
loss.backward()
optimizer.step()
print('Epoch {} | Loss {}'.format(epoch, loss.item()))
实验结果
测试了最流行的示例——GCN和GraphSAGE。对于全图训练,选择了基础数据集;而对于mini-batch方法,使用了来自OGB的数据集,其大小显著超过了基础数据集。例如,ogbn-products约有250万个节点和6100万条边,而ogbn-papers100M有1.11亿个节点和160万条边。表1显示了float和bfloat16的精度相似或没有显著变化。
| 模型 | 数据集 | 测试精度 (float) | 测试精度 (bfloat16) |
|---|---|---|---|
| gcn | citeseer | 71% | 71% |
| gcn | cora | 81% | 81% |
| gcn | pubmed | 79% | 79% |
| graphsage | citeseer | 71% | 71% |
| graphsage | cora | 81% | 81% |
| graphsage | pubmed | 78% | 78% |
| gcn minibatch | ogbn-paper100M | 57% | 57% |
| gcn minibatch | ogbn-products | 78% | 78% |
| graphsage minibatch | ogbn-paper100M | 62% | 61% |
| graphsage minibatch | ogbn-products | 76% | 74% |
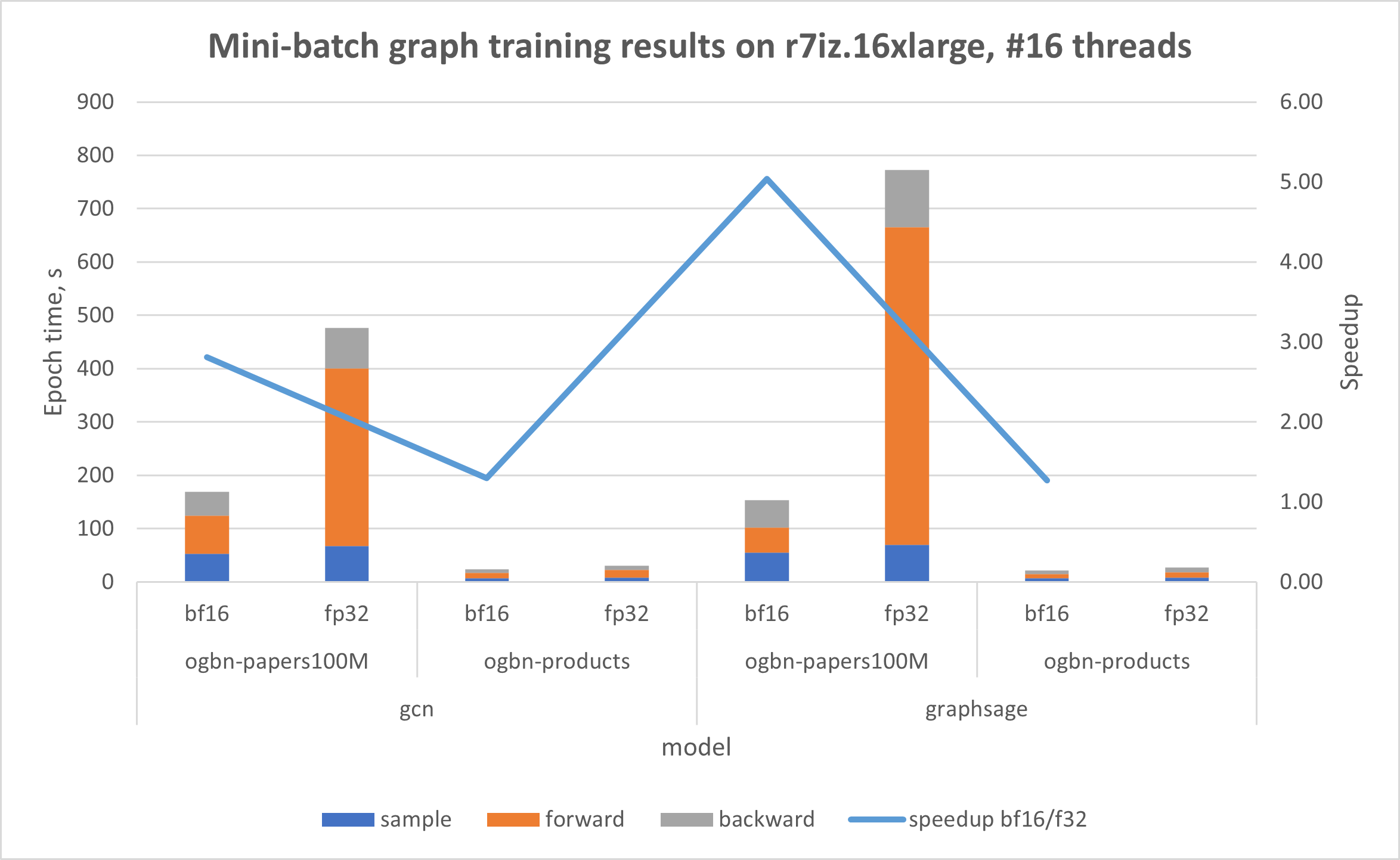
下图显示了在由第三代Intel Xeon 可扩展处理器(代号Ice Lake)驱动的AWS r6i上的结果,该处理器不具备原生的bfloat16指令;以及在基于第四代Intel Xeon 可扩展处理器(Sapphire Rapids)的AWS r7iz实例上的结果,该实例原生支持AVX512_BF16和AMX。在两个实验中,线程数都限制为16,这是在Intel® Xeon®上单次运行的最佳已知线程数。
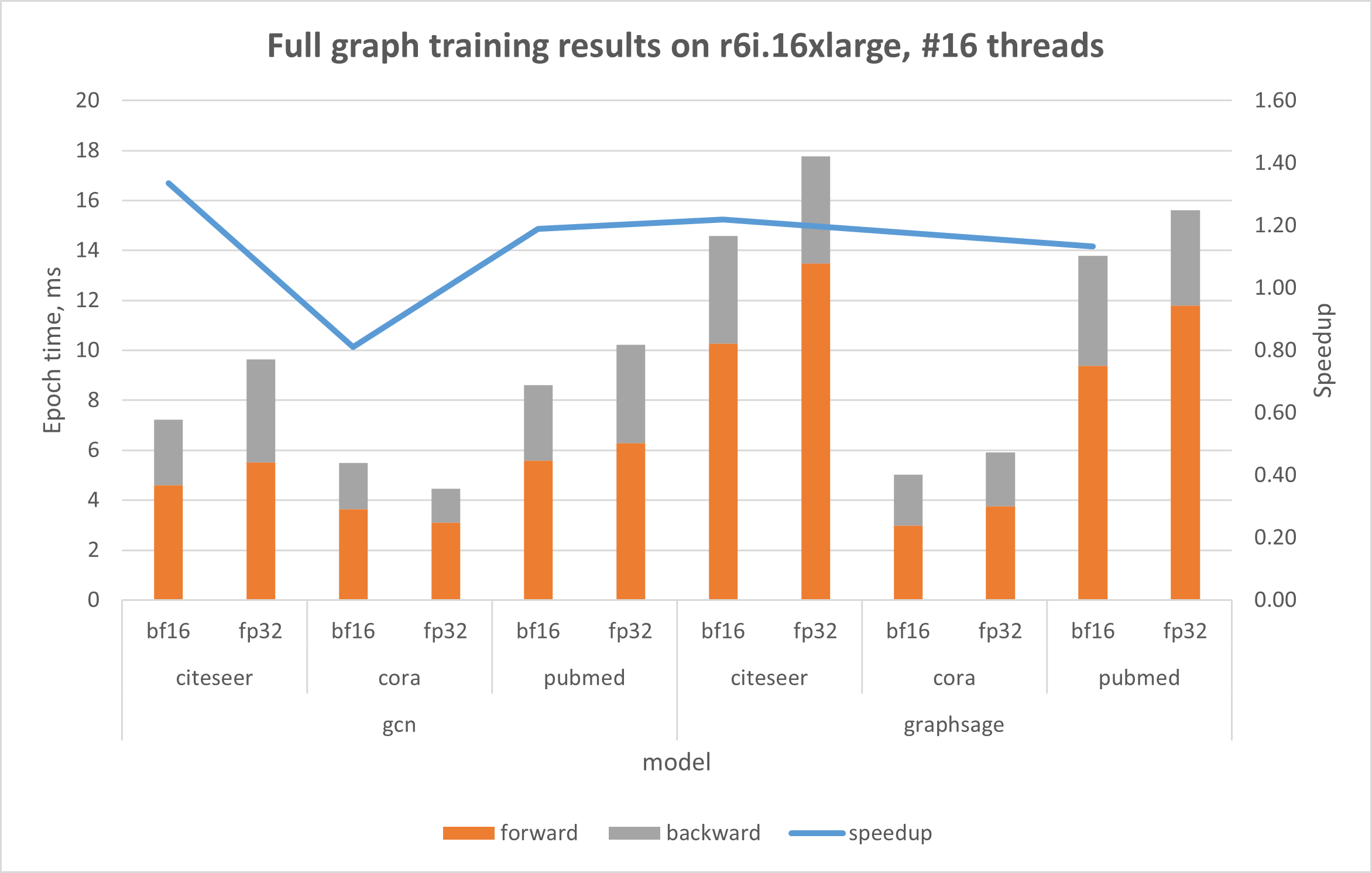
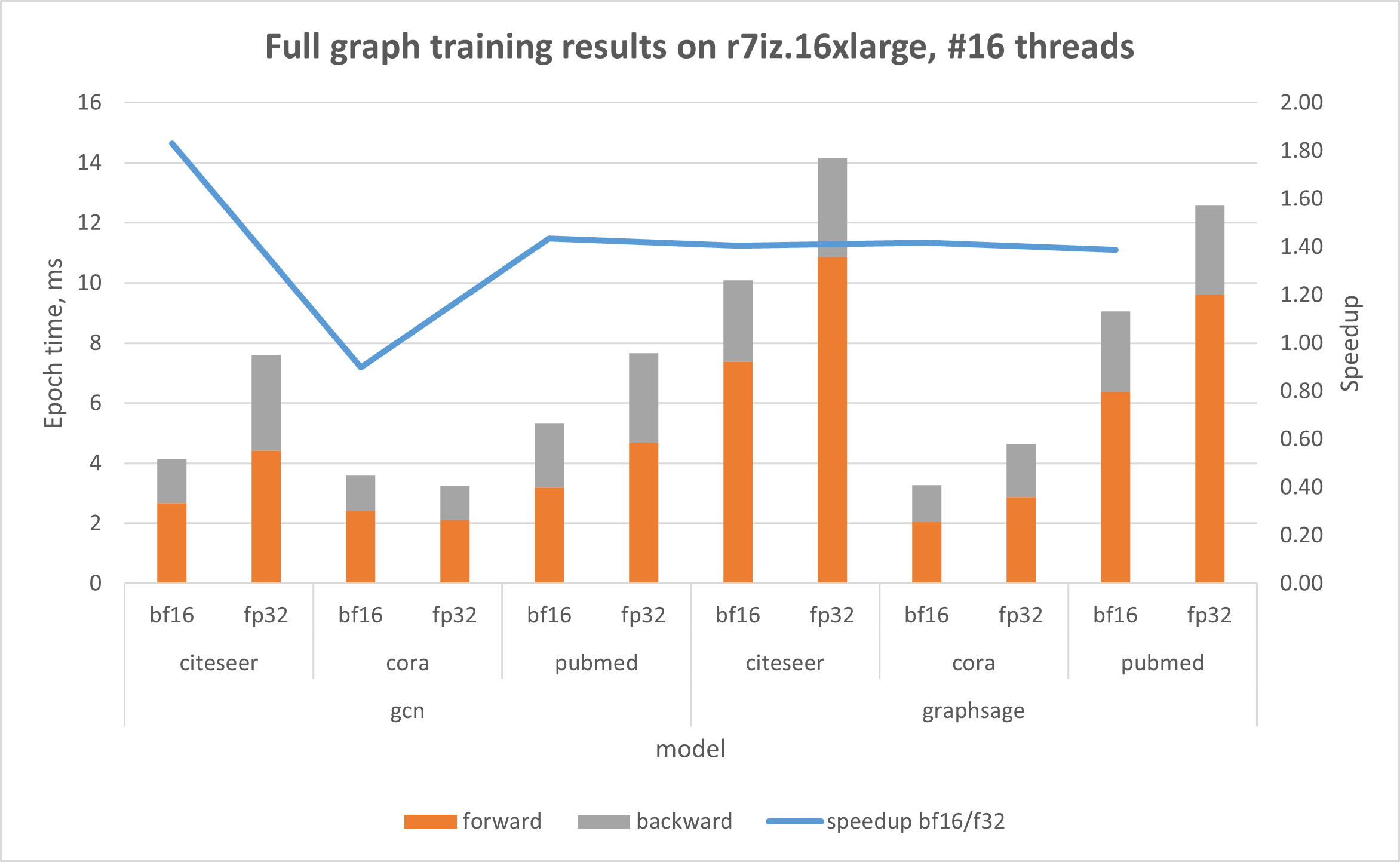
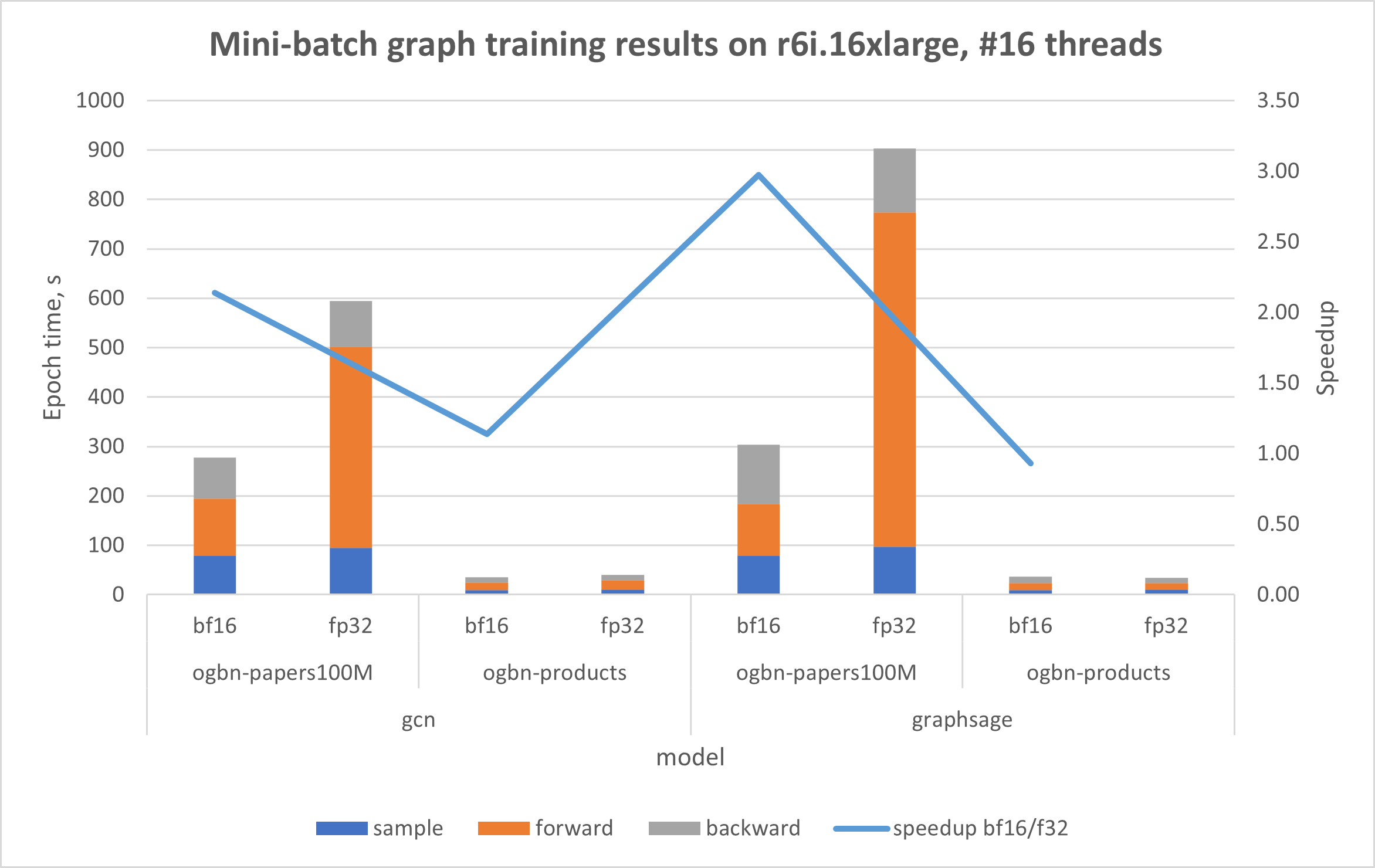
在使用bfloat16后,GNN训练效率在两种Intel® Xeon® 实例上都得到了提升。值得注意的是,在AWS r6i上的基础数据集方面,性能提升高达32%。同样,在使用Intel® AMX加速的r7iz上处理基础数据集时,使用bfloat16使训练性能提升高达92%。讨论OGB数据集的结果时(其大小显著大于基础数据集),r6i上的性能提升高达2.89倍,r7iz上的性能提升高达5.04倍。提供的图表显示,所有训练步骤的性能都得到了改进。在前向传播中观察到最显著的影响,使用bfloat16时速度提升高达12.7倍。
结论
强烈建议在Sapphire Rapids及更早一代的Intel Xeon 可扩展处理器上进行GNN训练时使用bfloat16数据类型,以提升性能。即使在Ice Lake上,bfloat16也能提高内存密集型操作的效率并降低训练成本。
尽管如此,DL框架中的某些方法可能无法完全支持或最优地利用CPU bfloat16指令。在这种情况下,我们建议通过少量epoch来评估float和bfloat16的性能,以确定最优选择。
10 八月
作者:Ilia Taraban,分类:博客